Code
EPID 684
Spatial Epidemiology
4/12/2022
Jon Zelner
[email protected]
epibayes.io
![]()
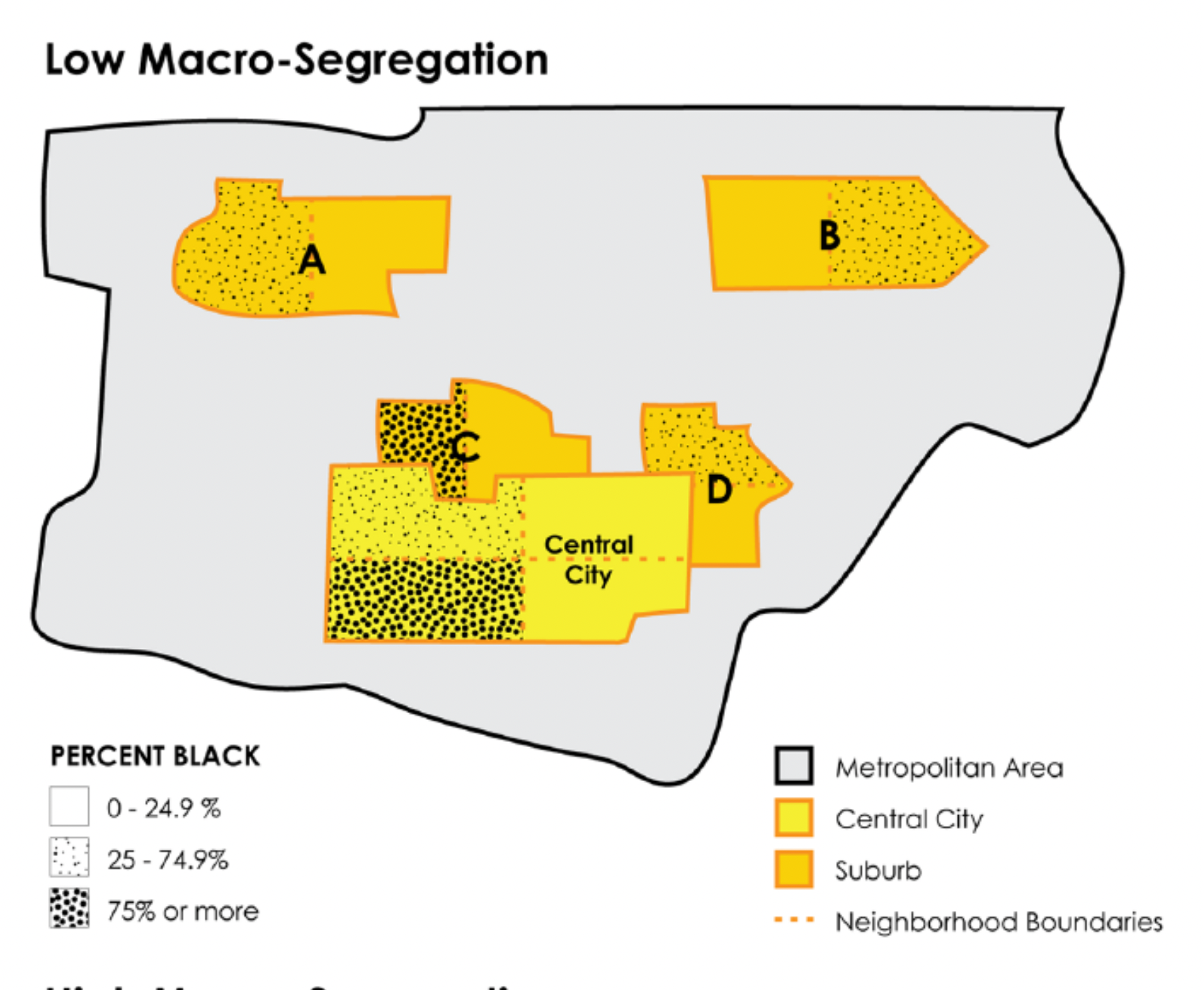
An example where segregation is primarily explained by within-unit variation. (from Lichter & Parisi (3))
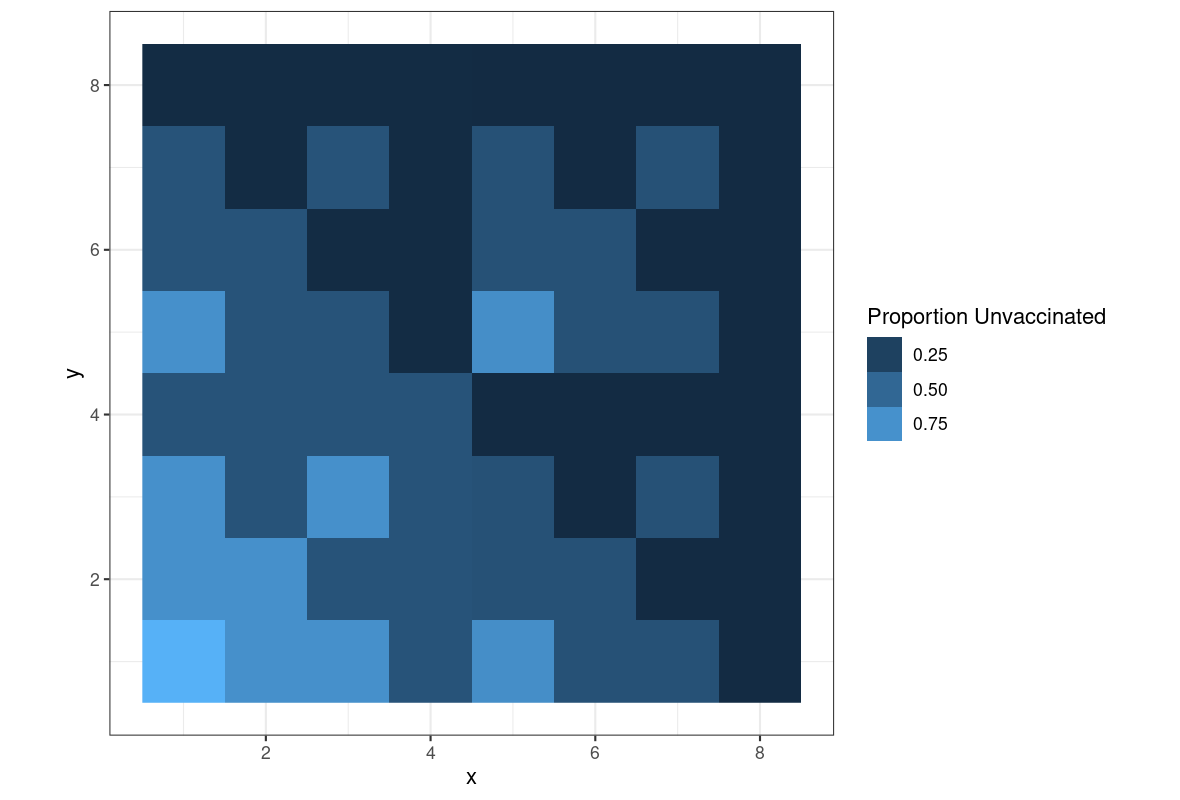
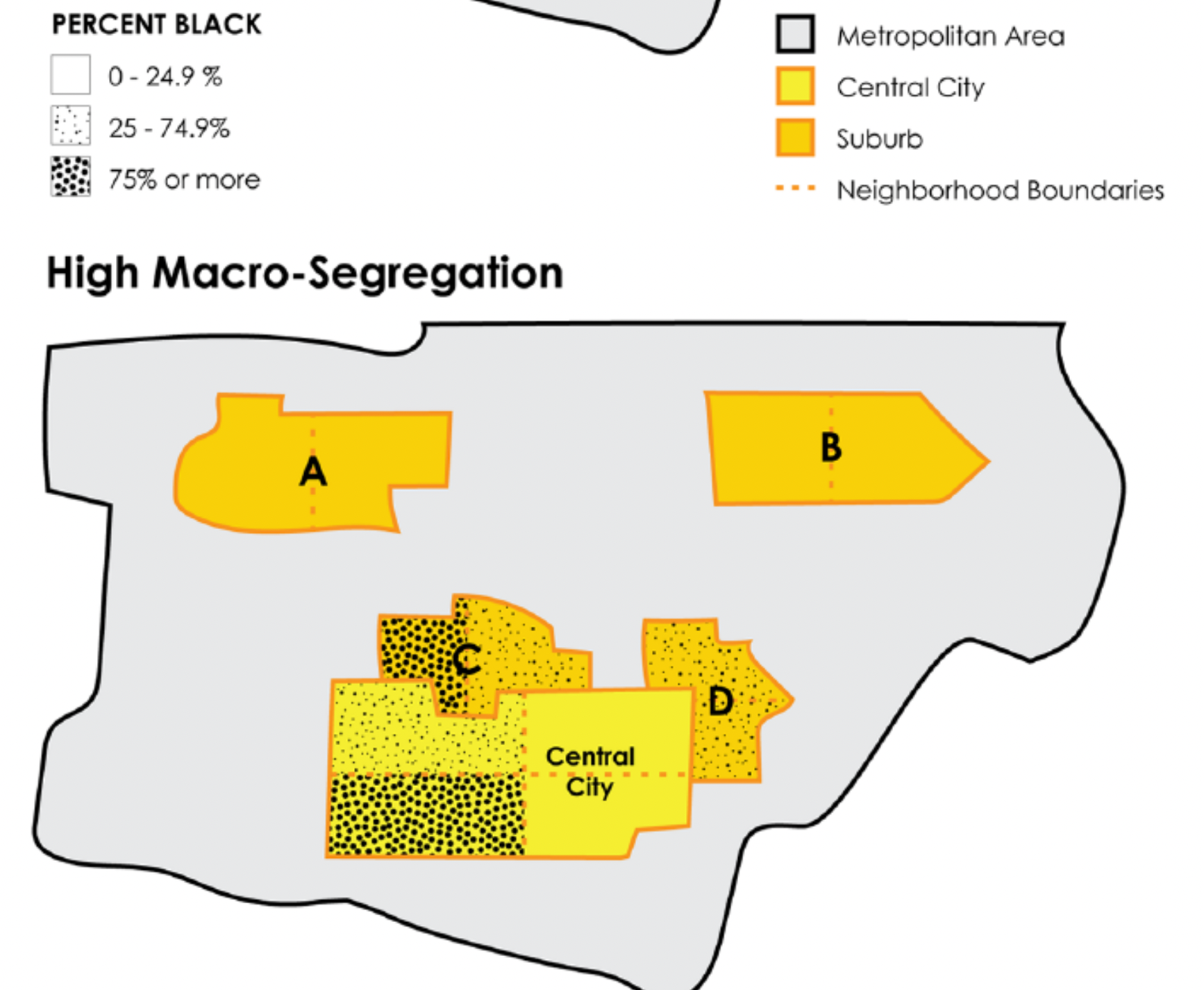
A pattern of segregation dominated by between-unit variation (3)
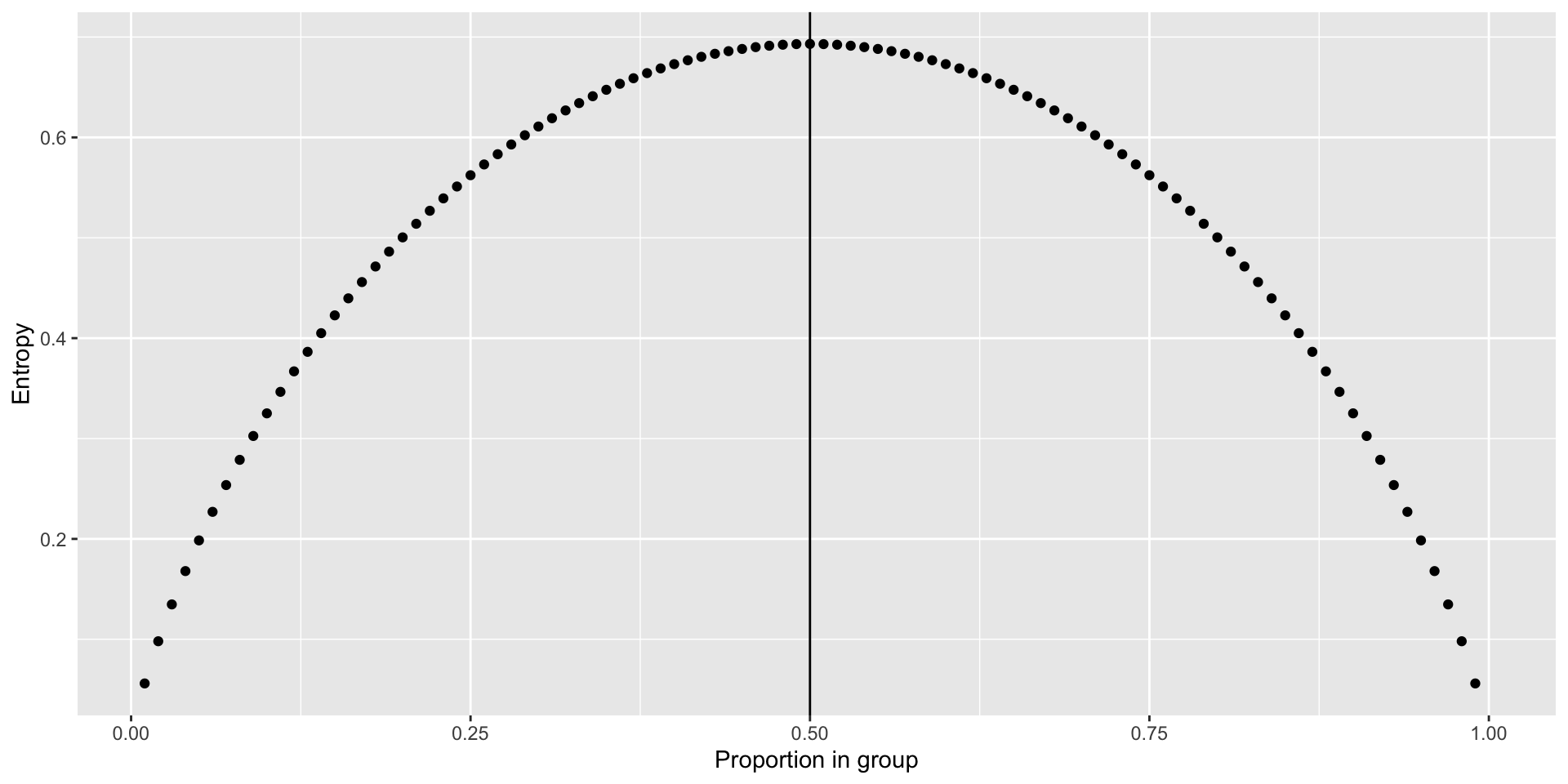
Entropy (\(E\)) is a measure of uncertainty
Maximum value \(\to\) Maximum Uncertainty
Minimum value Minimum Uncertainty
For two groups: \[E = p \frac{1}{p} + (1-p)\frac{1}{1-p}\]
Not limited to binary comparisons
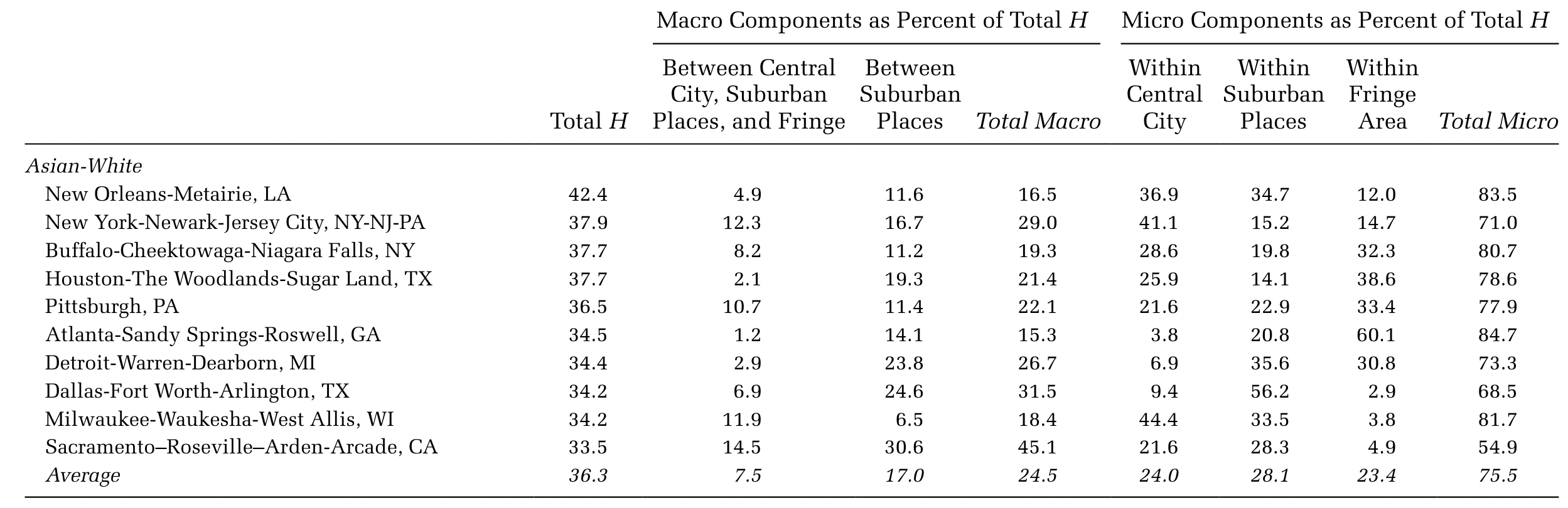
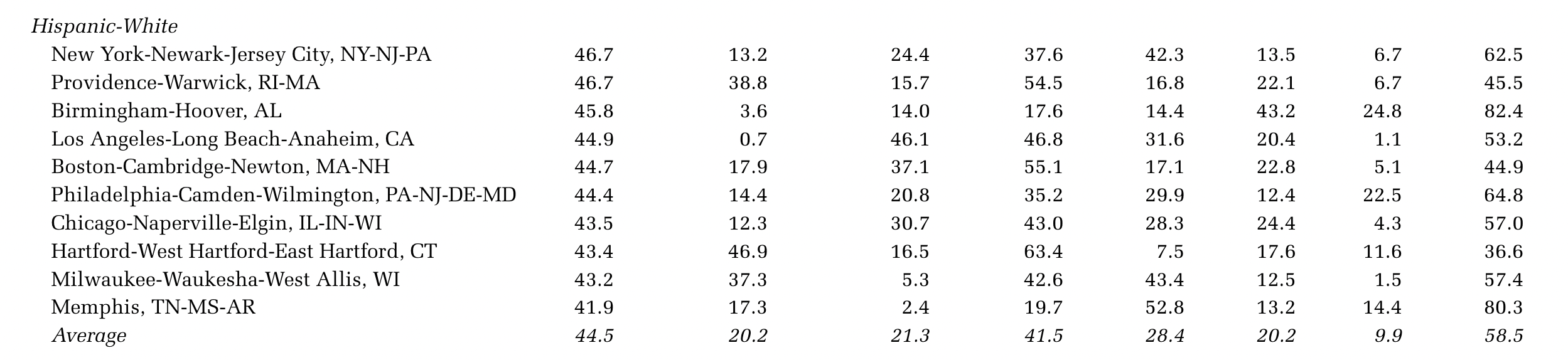
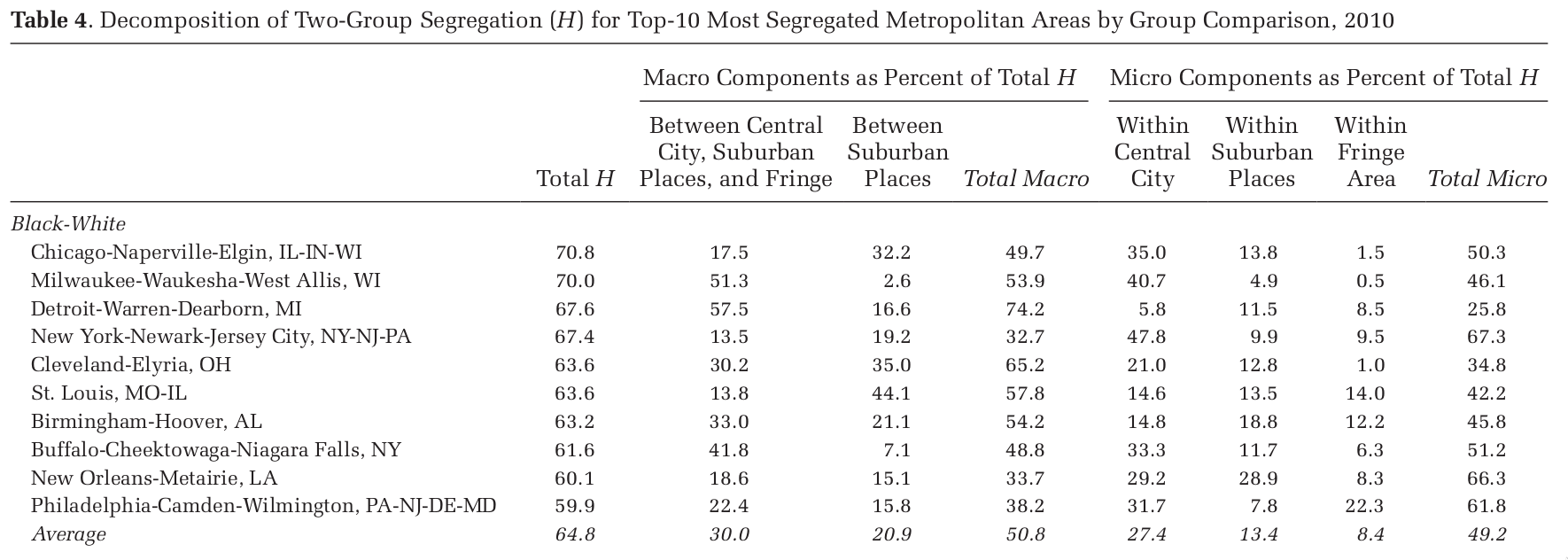
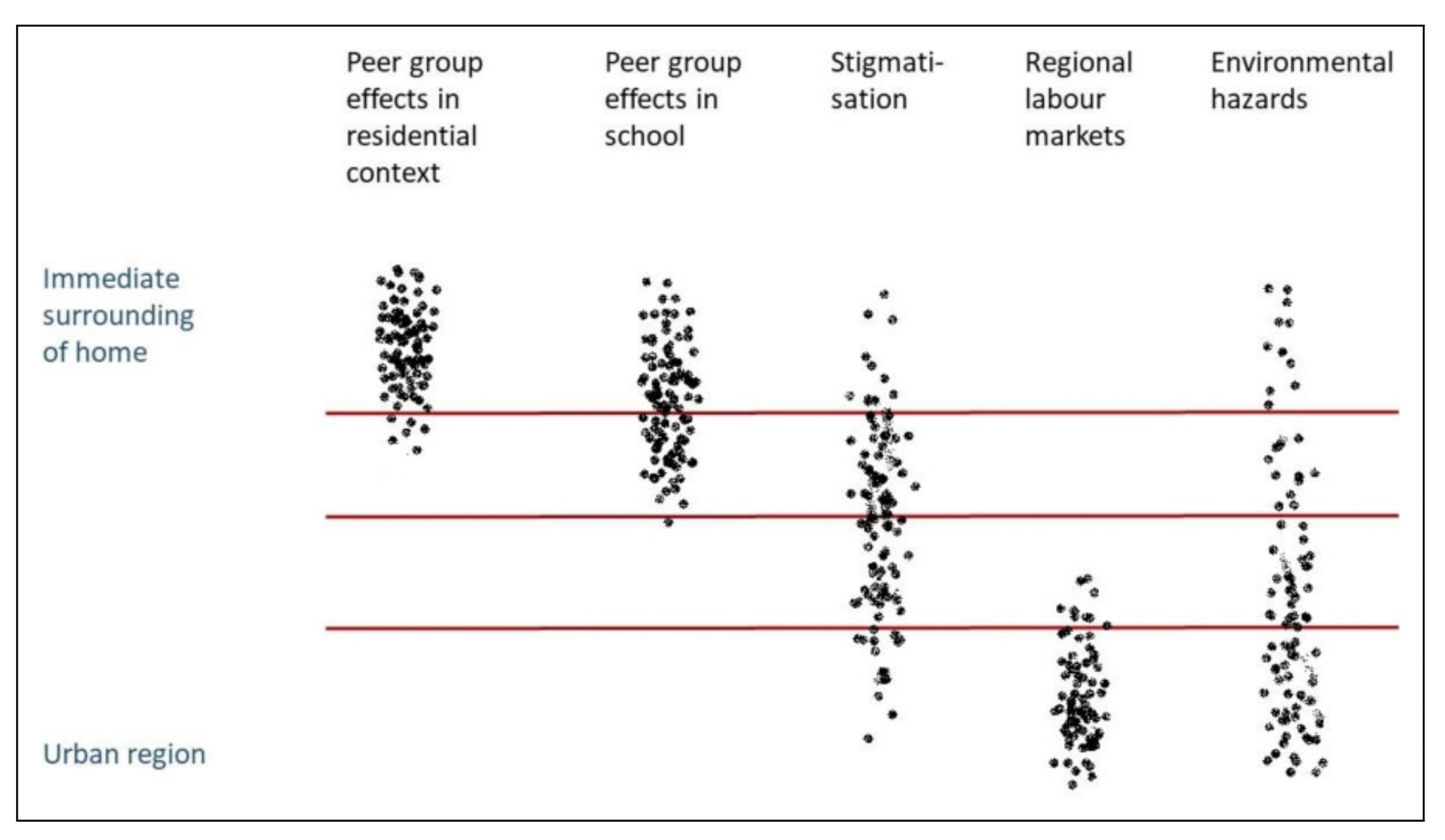 Can theses approaches help us pick more relevant scales of analysis? (Figure from (4))
Can theses approaches help us pick more relevant scales of analysis? (Figure from (4))
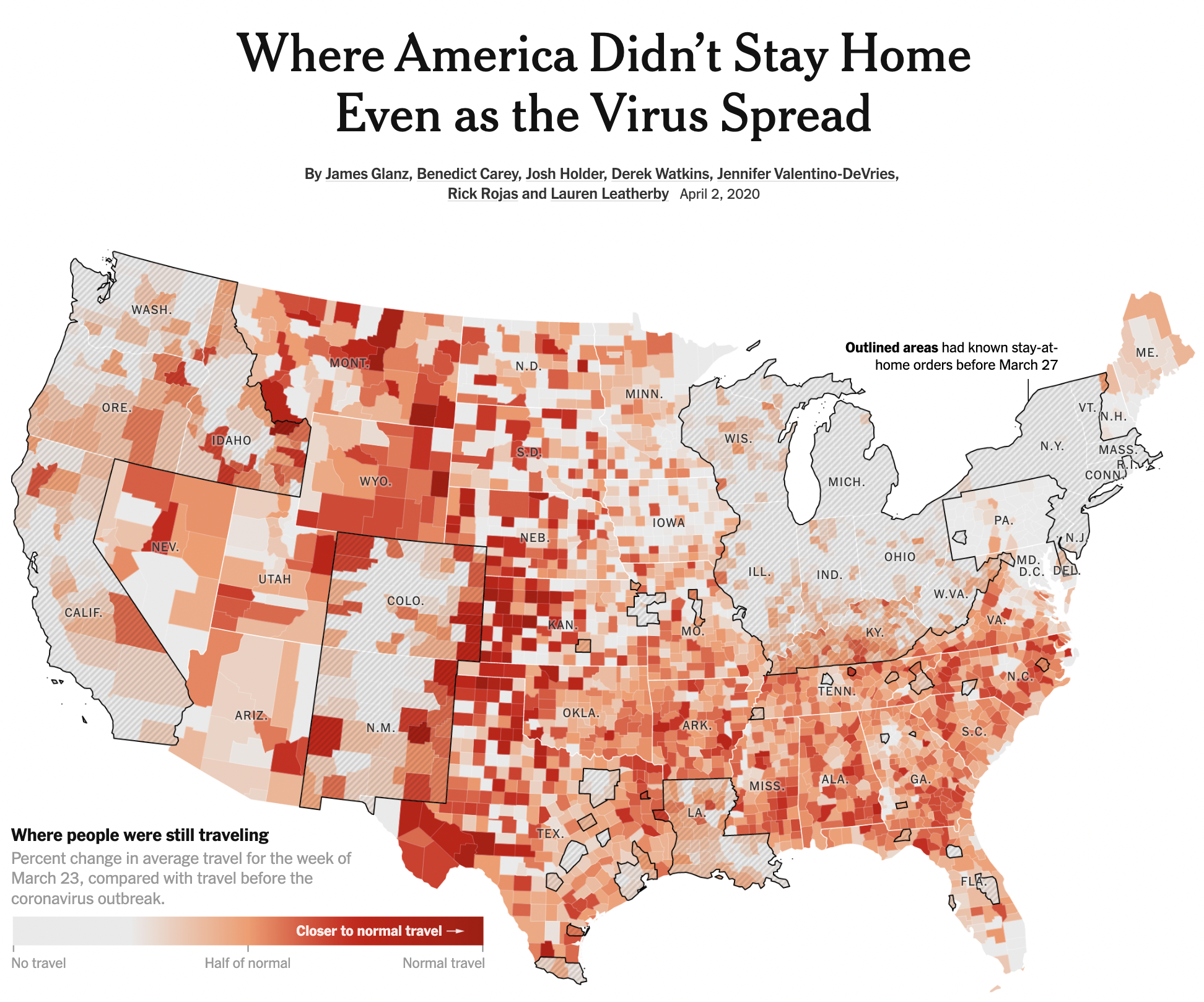
Relating mobility to COVID-19 spread in the early days of the pandemic (5)