08:00
Individual vs. Context vs. Space vs. Place
EPID 684
Spatial Epidemiology
University of Michigan School of Public Health
Jon Zelner
[email protected]
epibayes.io
![]()
Today’s Theme
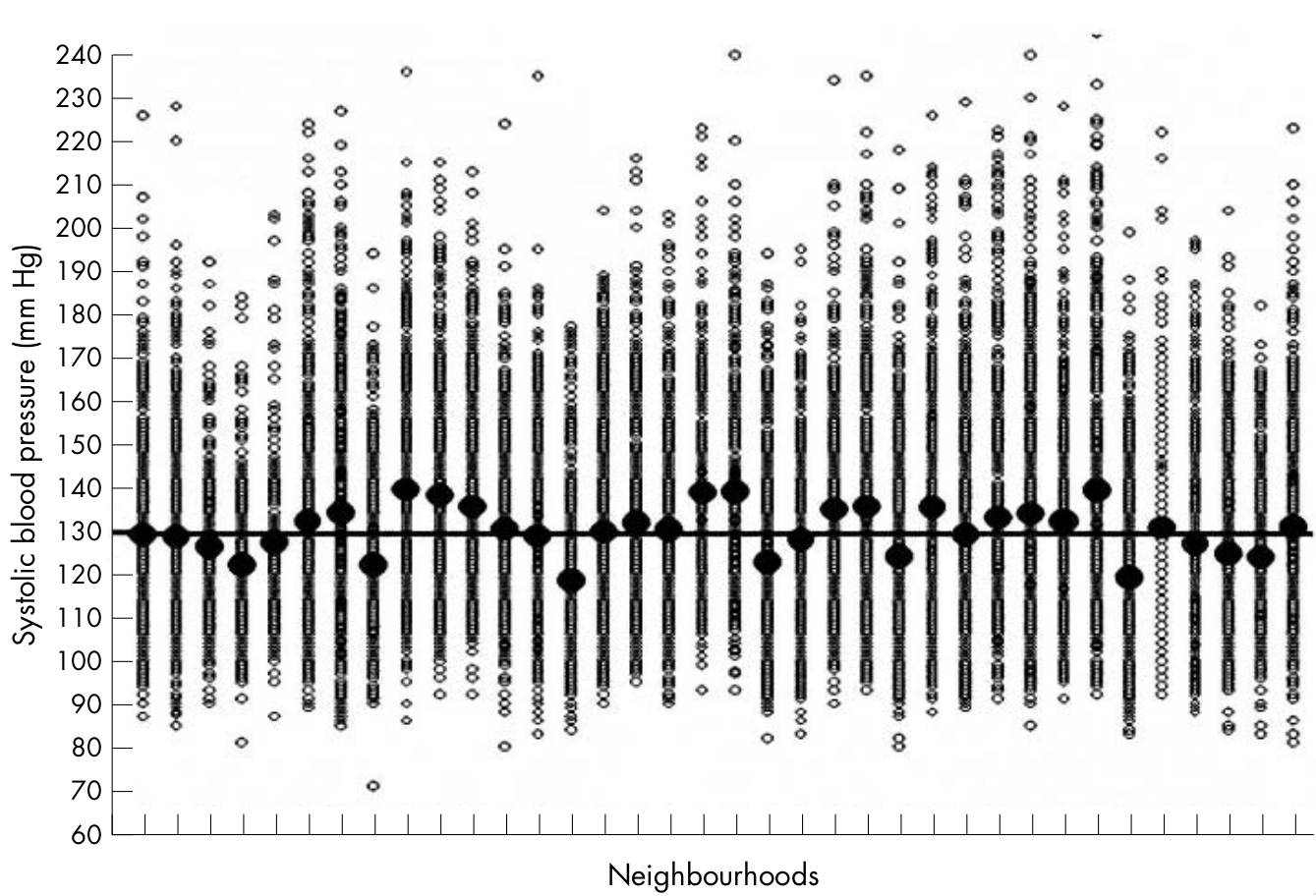
How can we characterize the relative importance of individual vs. contextual drivers of variation?
A worked example
Code
require(ggplot2)
mu_pop <- 120
sigma_pop <- 5
sigma_neighborhood <- 3
J <- 10
N <- 100
neighborhoods <- rep(1:J, N)
neighborhood_means <- rnorm(J, mu_pop, sqrt(sigma_neighborhood))
ind_sbp <- rnorm(N*J, neighborhood_means[neighborhoods], sqrt(sigma_pop))
hg <- ggplot(data.frame(x=ind_sbp)) + geom_histogram(aes(x=x), binwidth=0.5, colour = "black", fill = "white") + theme_bw() +
geom_vline(xintercept = mean(ind_sbp), linetype = "dashed") +
xlab("Systolic Blood Pressure (SBP)") +
ylab("N")
plot(hg)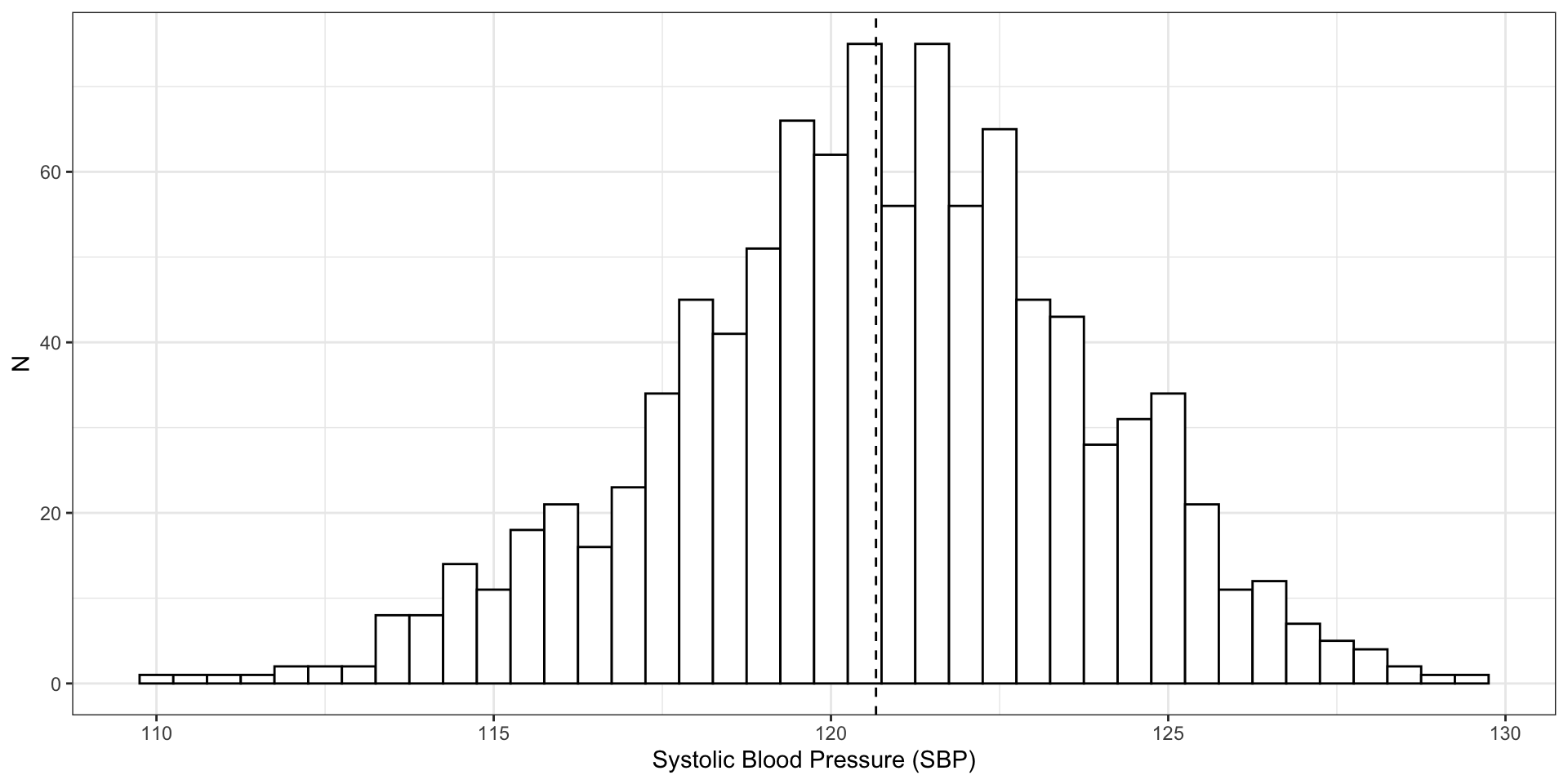
500 observations of blood pressure with \(\bar{x}\) = 120, \(\sigma^2\) = 8
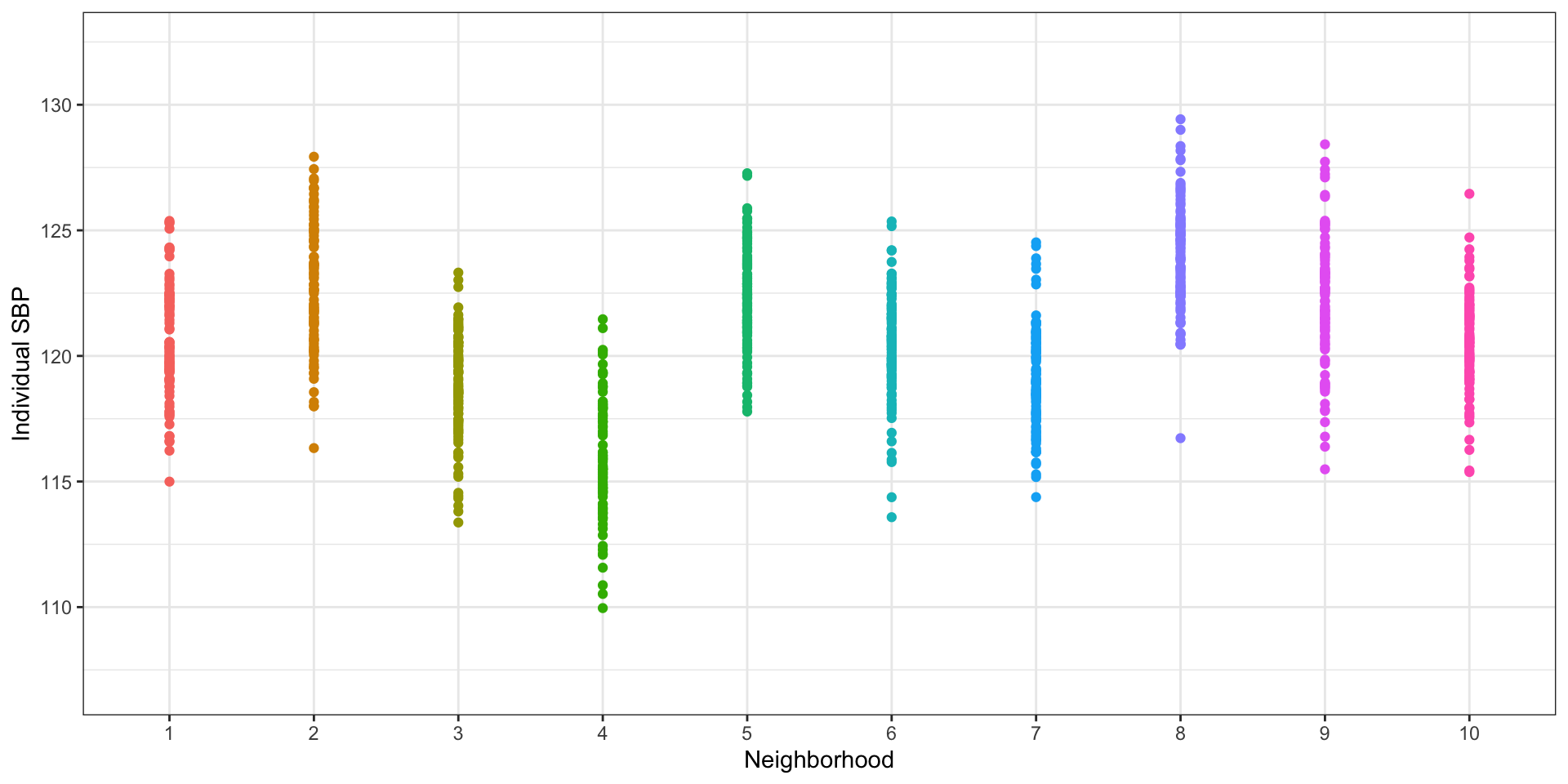
Plotting by neighborhood shows that there is more than just individual variation
Use neighborhood means to estimate between-neighborhood variance
Code
## Make a plot of neighborhood means, ordered from least to greatest
ig2 <- ggplot() +
geom_point(data = data.frame(x=as.factor(neighborhoods), y = ind_sbp), aes(x=x,y=y, colour = x)) +
geom_point(data = data.frame(x=as.factor(1:J), y = neighborhood_means), aes(x=x,y=y), shape = "x", size = 5) +
xlab("Neighborhood") +
ylab("Individual SBP") +
theme_bw() +
theme(legend.position = "none") +
ylim(sbp_limits)
plot(ig2)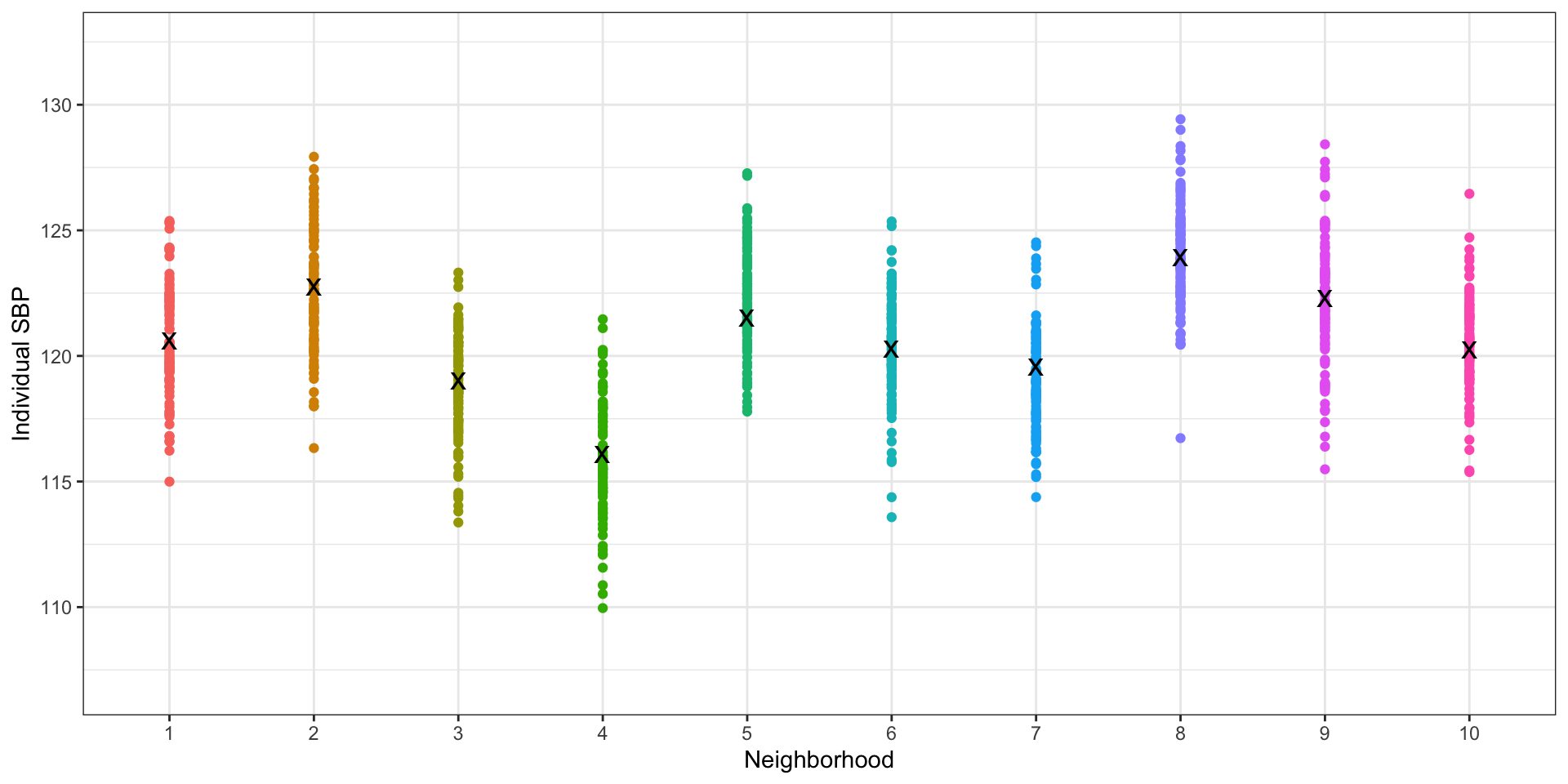
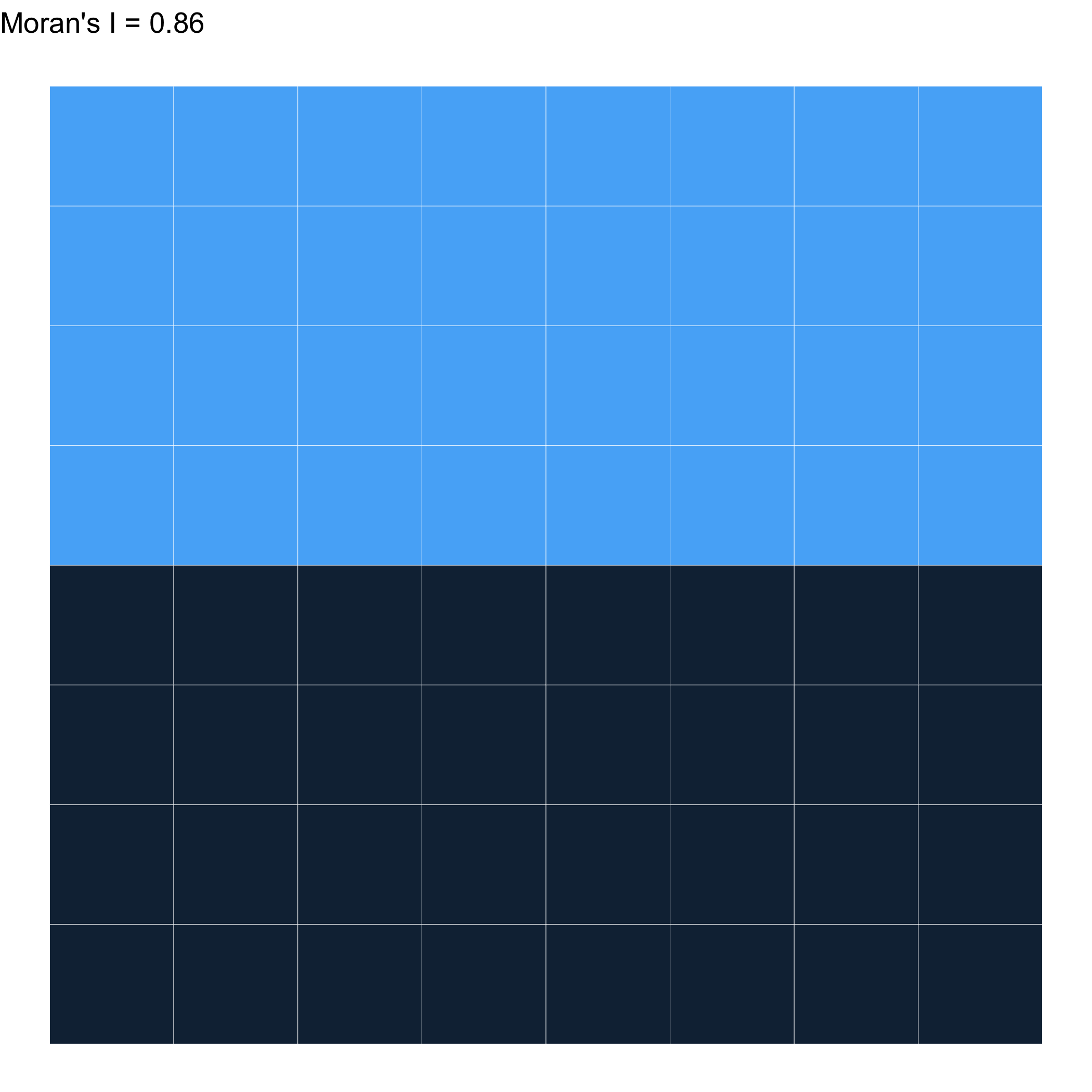
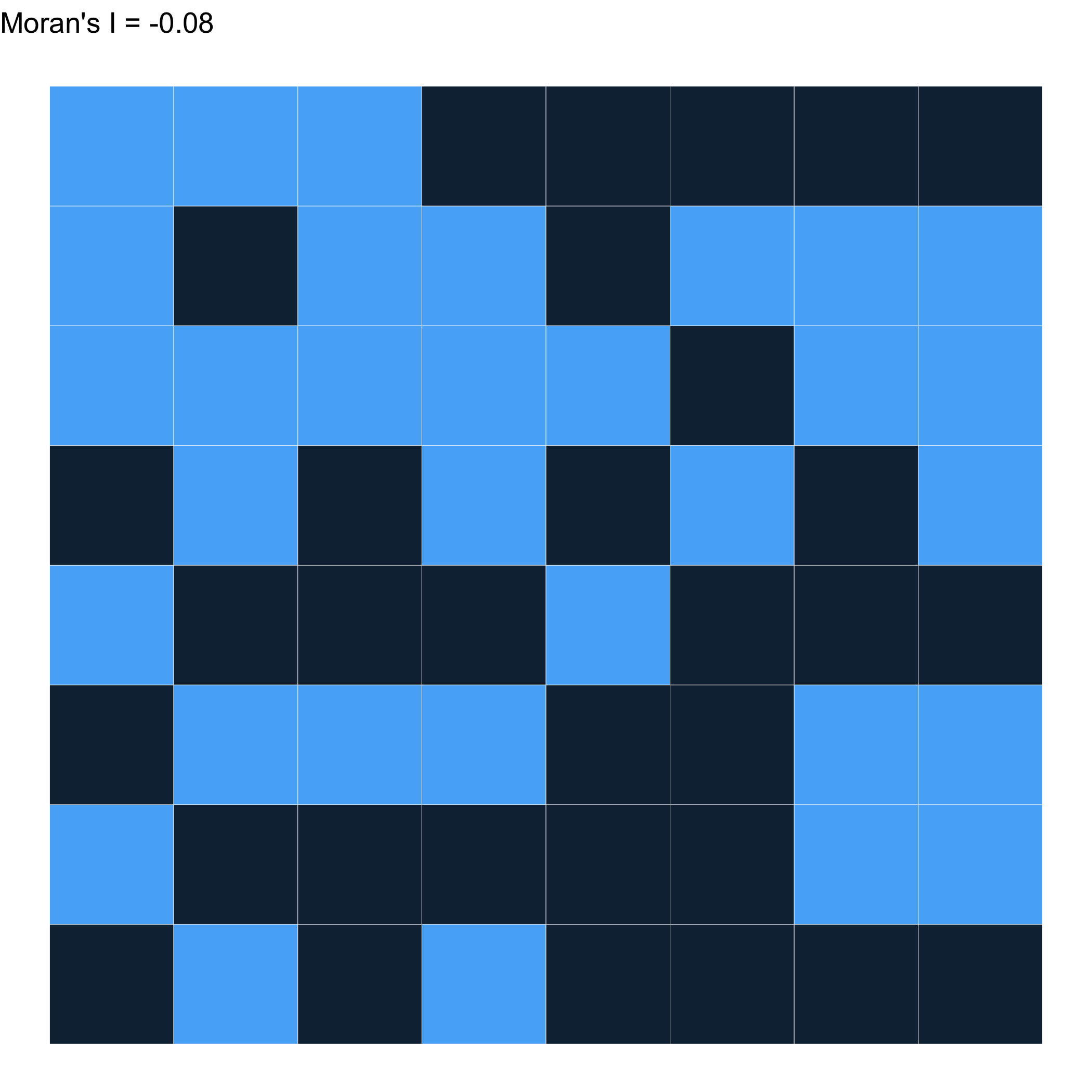
Let’s start by looking at how this works using Rook’s contiguity

As close as you can get to -1

As clustered as you can get \(\to\) 1
Randomly distributed \(\approx\) 0

Randomly distributed \(\approx\) 0
How does the choice of weights impact this?

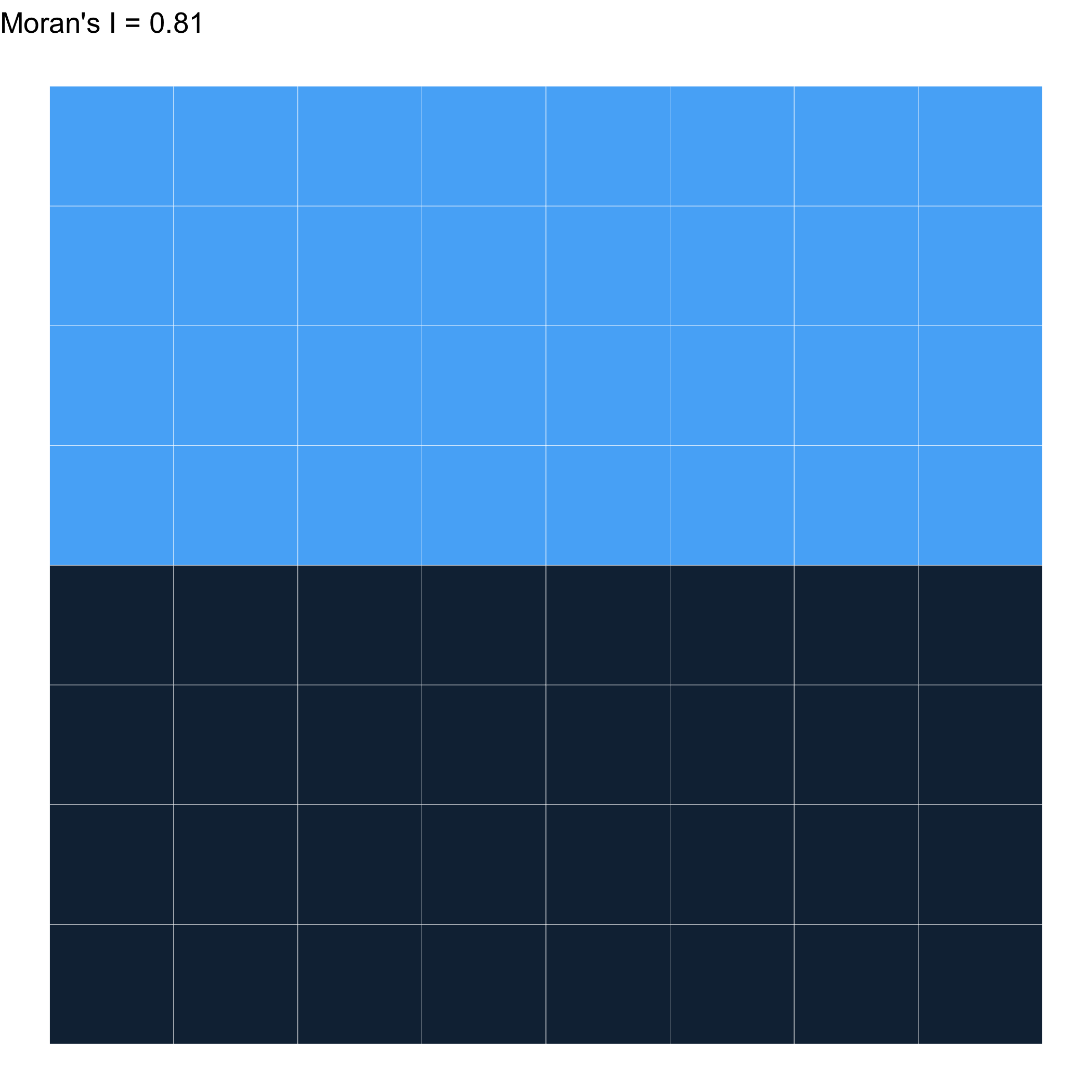
Let’s try with Queen’s contiguity!
Different weights \(\to\) A different result…


Next Time
Bringing in covariates to explain the drivers of space & place-based variation.