library(ggplot2)
library(tidyr)
library(dplyr)
library(arm)
library(bayesplot)
library(rstanarm)
library(purrr)
library(tidybayes)Re-creating the radon teaching example with rstanarm and tidybayes
Introduction
In this tutorial, we are going to replicate the analysis of household-level variation in radon exposure originally presented in Gelman (2006) (which is actually a tutorial version of Price, Nero, and Gelman (1996)). Our goal is to run the models described in the paper using regression models from base R as well as a Bayesian hierarchical model from the rstanarm package. Finally, we will reproduce Figures 1 & 2 from the original paper using ggplot2:
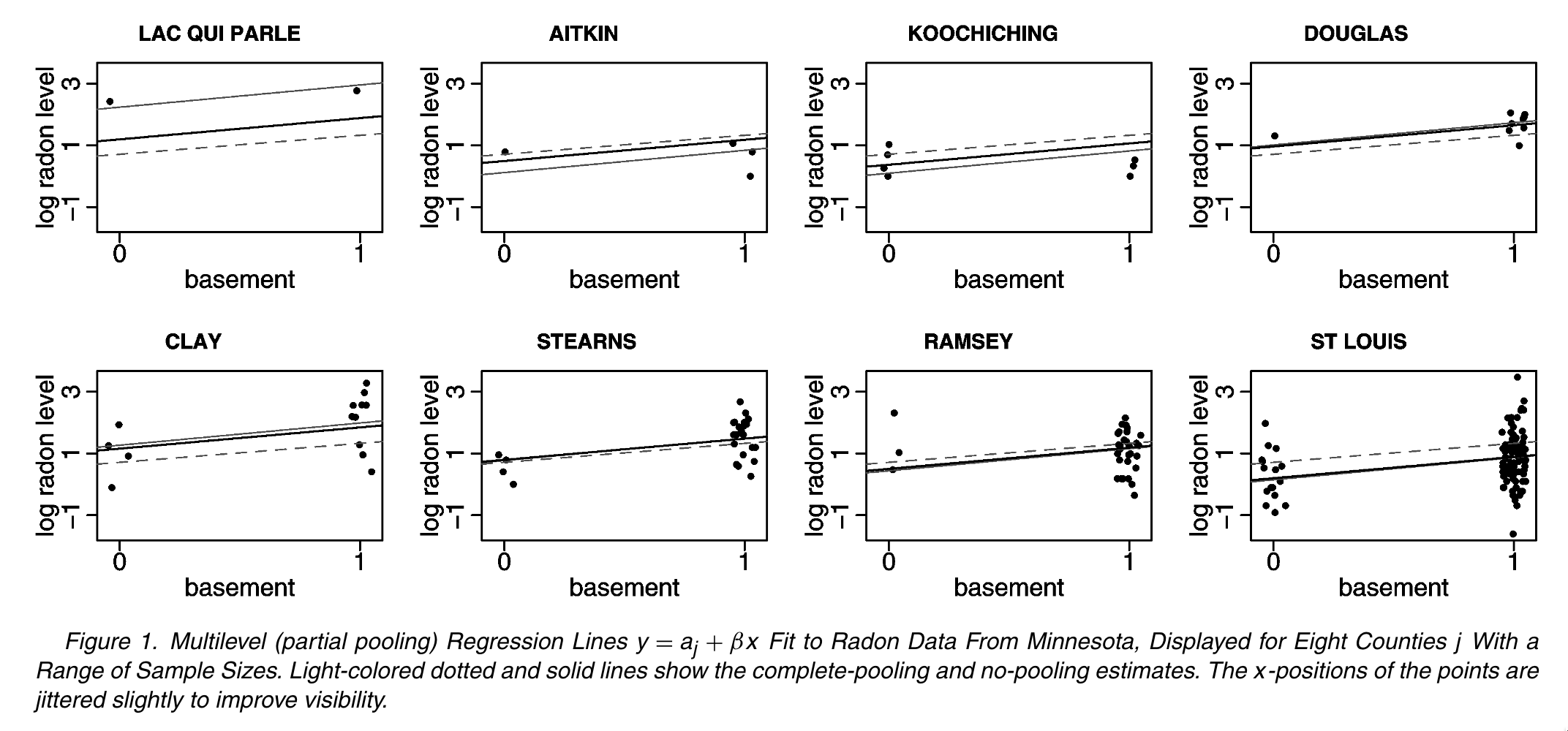
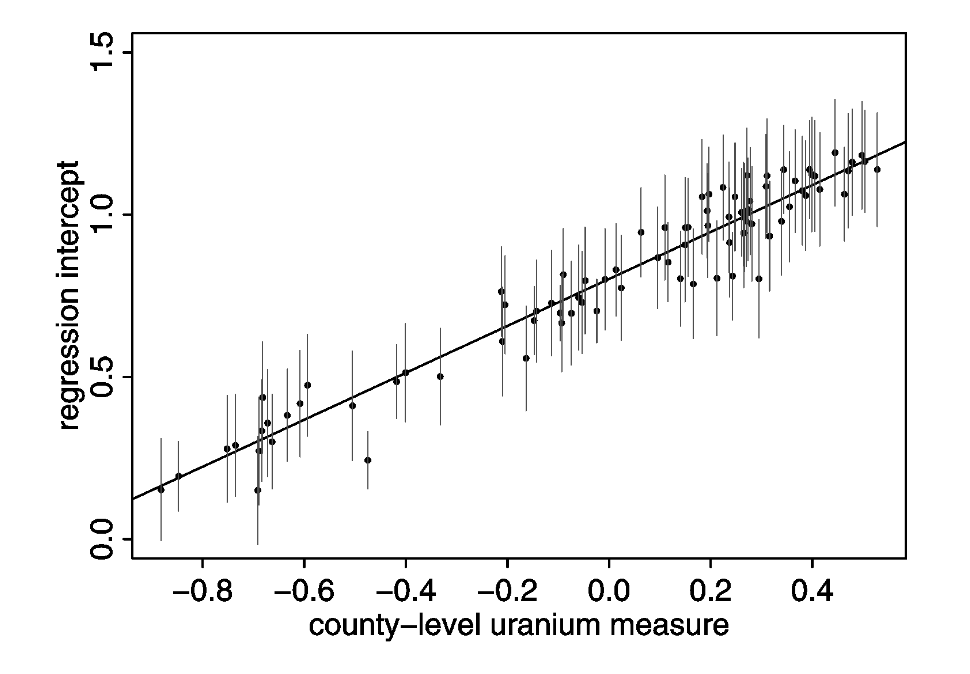
Preparing to run the examples
To be able to run the code below locally, please do the following:
Install or update to the latest version of RStudio. The tutorial code will be contained in a Quarto markdown document. Quarto (which powers this very website!) is an updated version of the venerable RMarkdown, and the newest versions of RStudio include Quarto support by default.
Set up your R/RStudio installation to be able to load the following packages using the following code:
If you are not sure if you have these installed or want to update to the latest versions, please paste this command into a running R session to download and install:
install.packages(c("ggplot2","tidyr","dplyr","bayesplot","rstanarm","purrr","tidybayes"))3.Download the zipfile containing this tutorial, unzip it and open an R session inside this newly unzipped radon directory.
Fitting the models
Setting up the workspace
First, we will load the relevant packages:
library(ggplot2)
library(tidyr)
library(dplyr)
library(bayesplot)
library(rstanarm)
library(purrr)
library(tidybayes)Data Preparation
First, lets take the raw radon dataset from the rstanarm package and recode the floor variable to be interpretable as the basement one from the original paper: some minor modifications and additonal datasets that we’ll use for the purposes of modeling and visualizing these data.
radon$basement <- 1 - radon$floorNow we can see that that the dataset has all of the variables we need:
floor county log_radon log_uranium basement
1 1 AITKIN 0.83290912 -0.6890476 0
2 0 AITKIN 0.83290912 -0.6890476 1
3 0 AITKIN 1.09861229 -0.6890476 1
4 0 AITKIN 0.09531018 -0.6890476 1
5 0 ANOKA 1.16315081 -0.8473129 1
6 0 ANOKA 0.95551145 -0.8473129 1🚪 Door 1: Full pooling!
This corresponds to a model in which we are assuming exactly no variation across locations in terms of the baseline level of radon. So, we can run a simple regression model where we assume that:
\[ y_{ij} = \alpha + \beta x_{ij} + \epsilon_{i} \]
Where \(x_{ij} = 1\) if a house has a basement and 0 otherwise.
In R, we can fit this model via least squares using a single line of code:
m1 <-lm(log_radon ~ basement, data = radon)We can call the summary function to get a description of the key coefficients and the goodness-of-fit:
lm(formula = log_radon ~ basement, data = radon)
coef.est coef.se
(Intercept) 0.78 0.06
basement 0.59 0.07
---
n = 919, k = 2
residual sd = 0.79, R-Squared = 0.07🚪 Door 2: No pooling
The second approach is the “No Pooling” one in which we allow the baseline intensity of radon in each county (represented by the intercept term \(\alpha_j\)) to vary, but we don’t do anything to constrain that variation. In other words, we treat each county as though it was independent.
However, to estimate a consistent effect of having a basement across all counties, we estimate a single \(\beta\) term. This leads to a model that looks like this:
\[ y_{ij} = \alpha_j + \beta x_{ij} + \epsilon_{i} \]
In R this is easy to implement, because we are implicitly asking the regression model to treat county as a categorical variable if we pass it to it as a factor datatype:
no_pool_m <- lm(log_radon ~ basement + log_uranium + county, data = radon)lm(formula = log_radon ~ basement + log_uranium + county, data = radon)
coef.est coef.se
(Intercept) 0.42 0.37
basement 0.69 0.07
log_uranium 0.32 0.60
countyANOKA 0.09 0.44
countyBECKER 0.48 0.53
countyBELTRAMI 0.67 0.43
countyBENTON 0.39 0.48
countyBIGSTONE 0.31 0.68
countyBLUEEARTH 0.83 0.51
countyBROWN 0.80 0.60
countyCARLTON 0.05 0.38
countyCARVER 0.43 0.50
countyCASS 0.52 0.47
countyCHIPPEWA 0.56 0.60
countyCHISAGO 0.21 0.48
countyCLAY 0.79 0.54
countyCLEARWATER 0.28 0.50
countyCOOK -0.23 0.60
countyCOTTONWOOD 0.06 0.63
countyCROWWING 0.26 0.40
countyDAKOTA 0.27 0.36
countyDODGE 0.63 0.63
countyDOUGLAS 0.60 0.49
countyFARIBAULT -0.42 0.57
countyFILLMORE 0.18 0.75
countyFREEBORN 0.94 0.51
countyGOODHUE 0.80 0.48
countyHENNEPIN 0.32 0.34
countyHOUSTON 0.52 0.66
countyHUBBARD 0.30 0.44
countyISANTI 0.22 0.57
countyITASCA 0.07 0.42
countyJACKSON 0.83 0.59
countyKANABEC 0.18 0.50
countyKANDIYOHI 0.94 0.54
countyKITTSON 0.51 0.55
countyKOOCHICHING 0.04 0.52
countyLACQUIPARLE 1.75 0.71
countyLAKE -0.40 0.44
countyLAKEOFTHEWOODS 0.99 0.51
countyLESUEUR 0.60 0.55
countyLINCOLN 1.08 0.67
countyLYON 0.75 0.59
countyMAHNOMEN 0.23 0.84
countyMARSHALL 0.53 0.44
countyMARTIN -0.05 0.51
countyMCLEOD 0.17 0.46
countyMEEKER 0.13 0.49
countyMILLELACS -0.07 0.60
countyMORRISON 0.11 0.41
countyMOWER 0.54 0.51
countyMURRAY 1.27 0.90
countyNICOLLET 0.99 0.59
countyNOBLES 0.71 0.68
countyNORMAN 0.10 0.63
countyOLMSTED 0.16 0.48
countyOTTERTAIL 0.60 0.40
countyPENNINGTON 0.11 0.54
countyPINE -0.24 0.43
countyPIPESTONE 0.62 0.68
countyPOLK 0.55 0.60
countyPOPE 0.11 0.70
countyRAMSEY 0.22 0.33
countyREDWOOD 0.78 0.61
countyRENVILLE 0.46 0.67
countyRICE 0.70 0.49
countyROCK 0.06 0.79
countyROSEAU 0.64 0.36
countySCOTT 0.70 0.43
countySHERBURNE 0.24 0.44
countySIBLEY 0.10 0.58
countySTLOUIS -0.03 0.31
countySTEARNS 0.38 0.43
countySTEELE 0.41 0.53
countySTEVENS 0.56 0.77
countySWIFT -0.18 0.61
countyTODD 0.65 0.54
countyTRAVERSE 0.76 0.69
countyWABASHA 0.69 0.50
countyWADENA 0.43 0.48
countyWASECA -0.47 0.58
countyWASHINGTON 0.31 0.34
countyWATONWAN 1.54 0.60
countyWILKIN 1.06 0.86
countyWINONA 0.41 0.60
countyWRIGHT 0.59 0.39
---
n = 919, k = 86
residual sd = 0.73, R-Squared = 0.29🚪 Door 3: Partial Pooling
Finally, we get to the partial pooling, hierarchical model in which we introduce a hierarchical prior to the model to allow our model to shrink observations from places with few observations towards the population mean. This allows us to avoid the pitfalls of overfitting associated with the no-pooling approach while not making the homogeneity assumptions associated with the full-pooling approach.
This works out to a multi-level model that allows random variation in household-level radon measurements as well as variation at the county level in radon levels above or below the amount predicted by the county-level soil uranium measure. Much like the no-pooling model, we can write outcomes for individuals as:
\[ y_{ij} = \alpha_j + \beta x_{ij} + \epsilon_{i} \]
However, rather than stopping there, we introduce a second level of random variation to the county-level intercepts, \(\alpha_j\).
\[ \alpha_j = \gamma_0 + \gamma \zeta_{j} + \epsilon_{j} \]
Where \(\epsilon_i \sim N(0, \sigma_i)\) and \(\epsilon_j \sim N(0, \sigma_j)\).
To fit this model, we’ll use the rstanarm package, which uses the Stan Bayesian modeling language under the hook to fit the model. This model introduces another piece of syntax to our equation, which now reads log_radon ~ basement + log_uranium + (1 | county). The interesting part of this is the (1 | county) which is a syntax used by rstanarm and other hierarchical modeling packages (such as lme4) to specify random intercepts (typically represented by a 1 in the matrix of regressors) for each of a set of clusters, in this case counties. In this model, the county-level intercept terms are implicitly assumed to be normally distributed with unknown variance \(\sigma_j\) which will be estimated when the model is fit.
We use the stan_lmer function to fit a hierarchical linear model with a normally-distributed response variable, as follows:
m2 <- stan_lmer(log_radon ~ basement + log_uranium + (1 | county), data = radon)Because this model is fit by MCMC, we can use draws from the posterior distribution to understand uncertainty in the model. For example, this visualization of the median prediction and credible intervals for the basement and uranium effects can be visualized using the mcmc_areas function from the bayesplot package:
posterior <- as.matrix(m2)
g2 <- mcmc_areas(posterior, pars = c("basement", "log_uranium"))
plot(g2)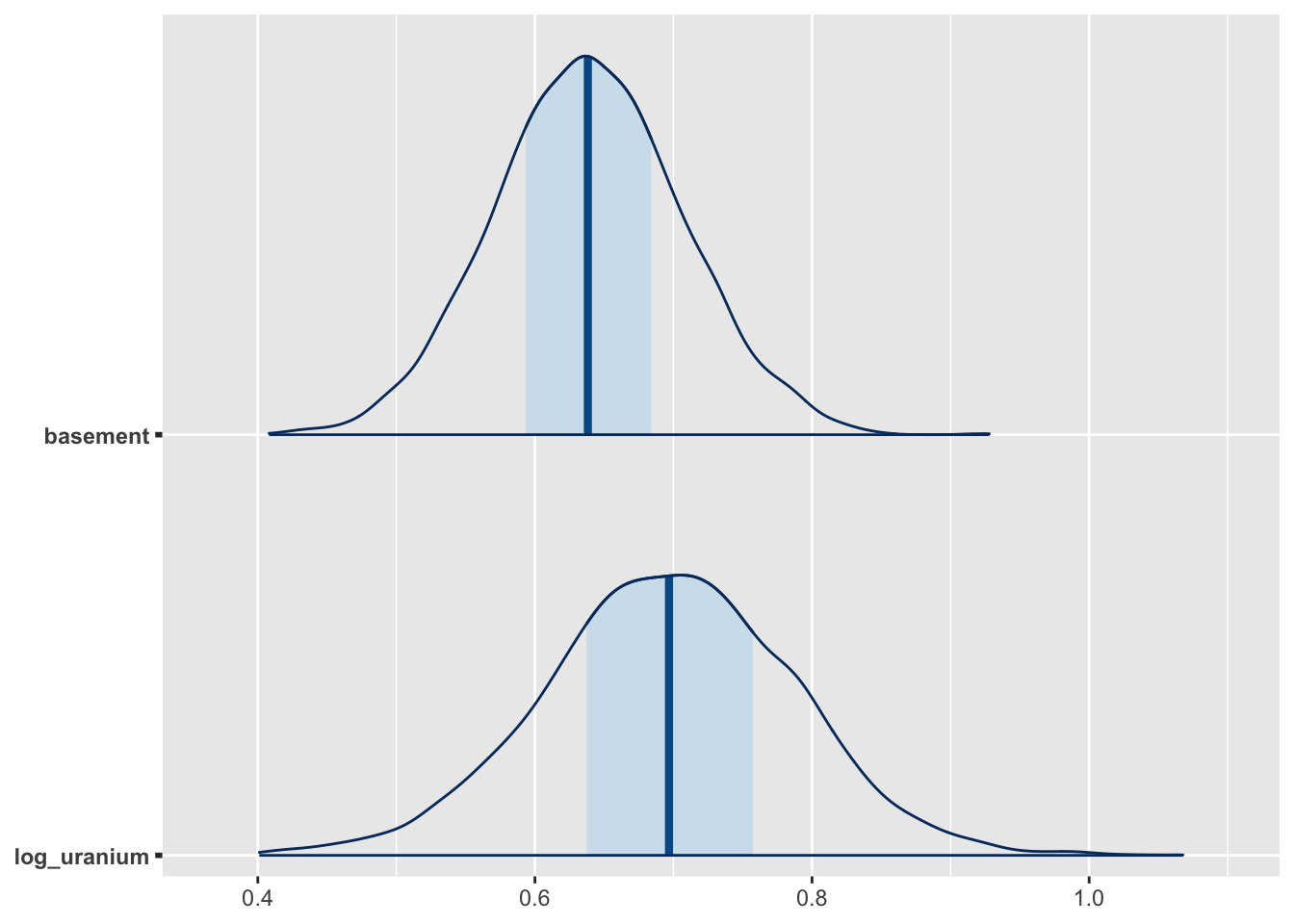
Making the Figures
Figure 1
Data Preparation
Since each row of radon dataset includes an observation of a single house, we need to work backwards to obtain the county-level soil uranium measure for each individual county. This is pretty straightforward to do using the dplyr package:
county_uranium <- radon %>%
group_by(county) %>%
summarize(log_uranium = first(log_uranium)) We will also make a second dataset that we will use for storing the predicted radon levels for households with and without basements each for county. This contains 2 entries for each county, representing observations taken in the basement or on the first floor.
county_uranium_tmp_1 <- county_uranium
county_uranium_tmp_1$basement <- 1
county_uranium_tmp_2 <- county_uranium
county_uranium_tmp_2$basement <- 0
county_dummy_df <- rbind(county_uranium_tmp_1, county_uranium_tmp_2)Now, we will take each of our fitted models (fully pooled, unpooled and partially pooled) and put their predicted values into our plotting dataset
county_dummy_df$pooled_pred <- predict(m1, county_dummy_df)
county_dummy_df$no_pool_pred <- predict(no_pool_m, county_dummy_df)Warning in predict.lm(no_pool_m, county_dummy_df): prediction from a rank-
deficient fit may be misleadingBecause the partial pooling model was fit using MCMC, we will take a slightly different approach and use the median of the posterior predictive distribution for each observation, which is analogous to (but not exactly the same as) the OLS predictions from the other models:
## Gives posterior median for each prediction.
county_dummy_df$partial_pred <- posterior_predict(m2, county_dummy_df) %>%
apply(2,median) Plotting
To re-create Figure 1, we will subset out the observed data and predictions for the 8 counties included in the original figure:
## Place the county names in a vector we will use to keep track of them
fig_1_counties <-
c(
"LACQUIPARLE",
"AITKIN",
"KOOCHICHING",
"DOUGLAS",
"CLAY",
"STEARNS",
"RAMSEY",
"STLOUIS"
)
# First, using the `county_dummy_df` with the basement/non-basement predictions in it,
# subset out the relevant counties and make a new county factor variable which
# will be used to ensure that the counties in Fig. 1 plot in the right order
county_df_fig_1 <- county_dummy_df %>%
filter(county %in% fig_1_counties) %>%
mutate(county2 = factor(county, levels = fig_1_counties)) %>%
arrange(county)
## Now select out the households in the original data that
## are in each county and create another county-level factor
## variable in the same order
pred_counties <- radon %>% filter(county %in% fig_1_counties) %>%
mutate(county2 = factor(county, levels = fig_1_counties))Once we have the datasets together for the figure, we can begin constructing it using ggplot2:
g <- ggplot() +
## The geom_jitter geom plots the log_radon values for each household and
## jitters the points slightly to avoid overplotting.
geom_jitter(
data = pred_counties,
aes(x = basement, y = log_radon, group = county2),
height = 0,
width = 0.1
) +
## This superimposes the partial-pooling (α + β x_i + ϵ_i +ϵ_j) predictions
## over the raw data
geom_line(
data = county_df_fig_1,
aes(x = basement, y = partial_pred, group = county2),
linetype = "solid",
colour = "gray"
) +
## No-pooling predictions (α_{ij} + β x_i + ϵ_i)
geom_line(
data = county_df_fig_1,
aes(x = basement, y = no_pool_pred, group = county2)
) +
## Full pooling predicitons (α + β x_i + ϵ_i)
geom_line(
data = county_df_fig_1,
aes(x = basement, y = pooled_pred, group = county2),
linetype = "dashed"
) +
## Finally, use facet_wrap to arrange the panels in two
## rows of four
facet_wrap(vars(county2), nrow = 2) +
xlab("basement") +
ylab("log radon level") +
theme_bw() +
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank())
plot(g)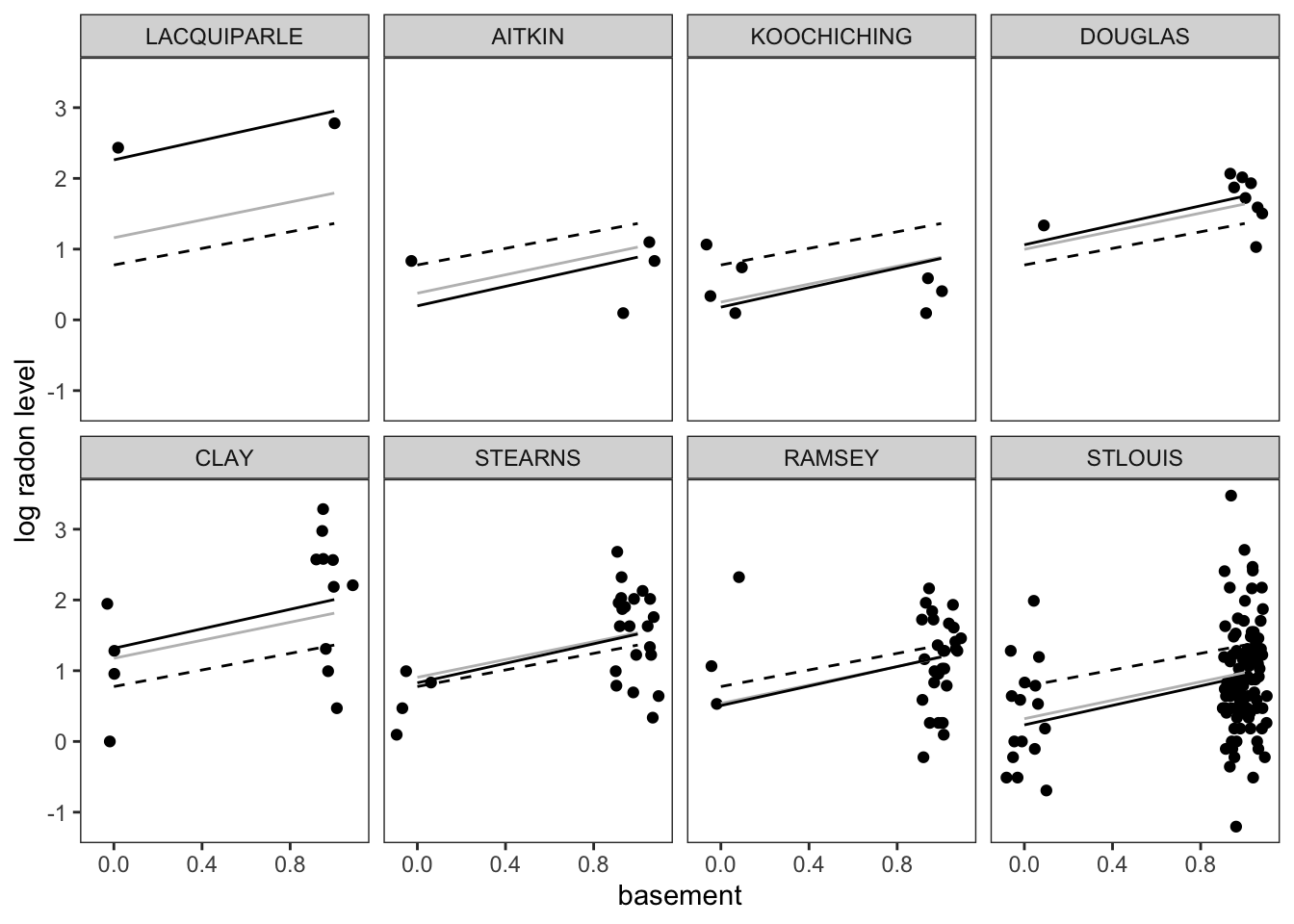
Figure 2
Figure 2 reproduces the relationship between the county-level random intercepts, \(\alpha_j\) and the expected level of radon at a county level as a function of county-level soil uranium.
Data Preparation
The following code allows us to extract predictions at the county level using our prediction dataset. To do this, we use the predicted_draws function from the tidybayes package, which lets us sample from the posterior distribution of the fitted model. The median_qi function, also from tidybayes, lets us calculate the width of a 1 standard error interval (equivalent to the range containing ~17% of the posterior probability mass around the posterior median) used in the original Figure 1 from Gelman (2006):
dd <- predicted_draws(m2, county_dummy_df) %>%
median_qi(.width = 0.17) %>%
filter(basement == 0)In order to calculate the predicted mean radon at a county level, we need to access the coefficients corresponding to the level two model, including the intercept \(\gamma_0\) and the effect of a 1-log change in log-uranium on predicted log-radon, \(\gamma_1\). In order to get these values out of the model, we can use the gather_draws function from tidybayes, which allows us to access the posterior distributions for each of these parameters:
uranium_coefs <-
gather_draws(m2, c(`(Intercept)`, log_uranium)) %>% median_qi()Now it is as simple as calculating the linear predictor \(\gamma_0 + \gamma_1 z_j\), where \(z_j\) is the log-uranium measure for the j-th county, and storing this information in a data frame we will use for plotting:
log_uranium_range <-
seq(min(county_uranium$log_uranium) - .1,
max(county_uranium$log_uranium) + .1,
by = 0.1)
pred_log_radon <-
uranium_coefs$.value[1] + uranium_coefs$.value[2] * log_uranium_range
median_radon_pred <-
data.frame(log_uranium = log_uranium_range, .prediction = pred_log_radon)Plotting
Now, we can build this figure up one step at a time, starting with our mean predictions:
g <- ggplot(dd) +
geom_line(data = median_radon_pred, aes(x = log_uranium, y = .prediction))
plot(g)
The next step is to then add the median predictions (points) and 1 SE errorbars to the plot, and then fix the theme to match the original figure, et voilà!
g <- g + geom_point(aes(x = log_uranium, y = .prediction, group = county)) +
geom_errorbar(aes(
x = log_uranium,
y = .prediction,
ymin = .lower,
ymax = .upper
)) +
theme_bw() + theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank()) +
xlab("county-level uranium measure") +
ylab("regression intercept")
plot(g)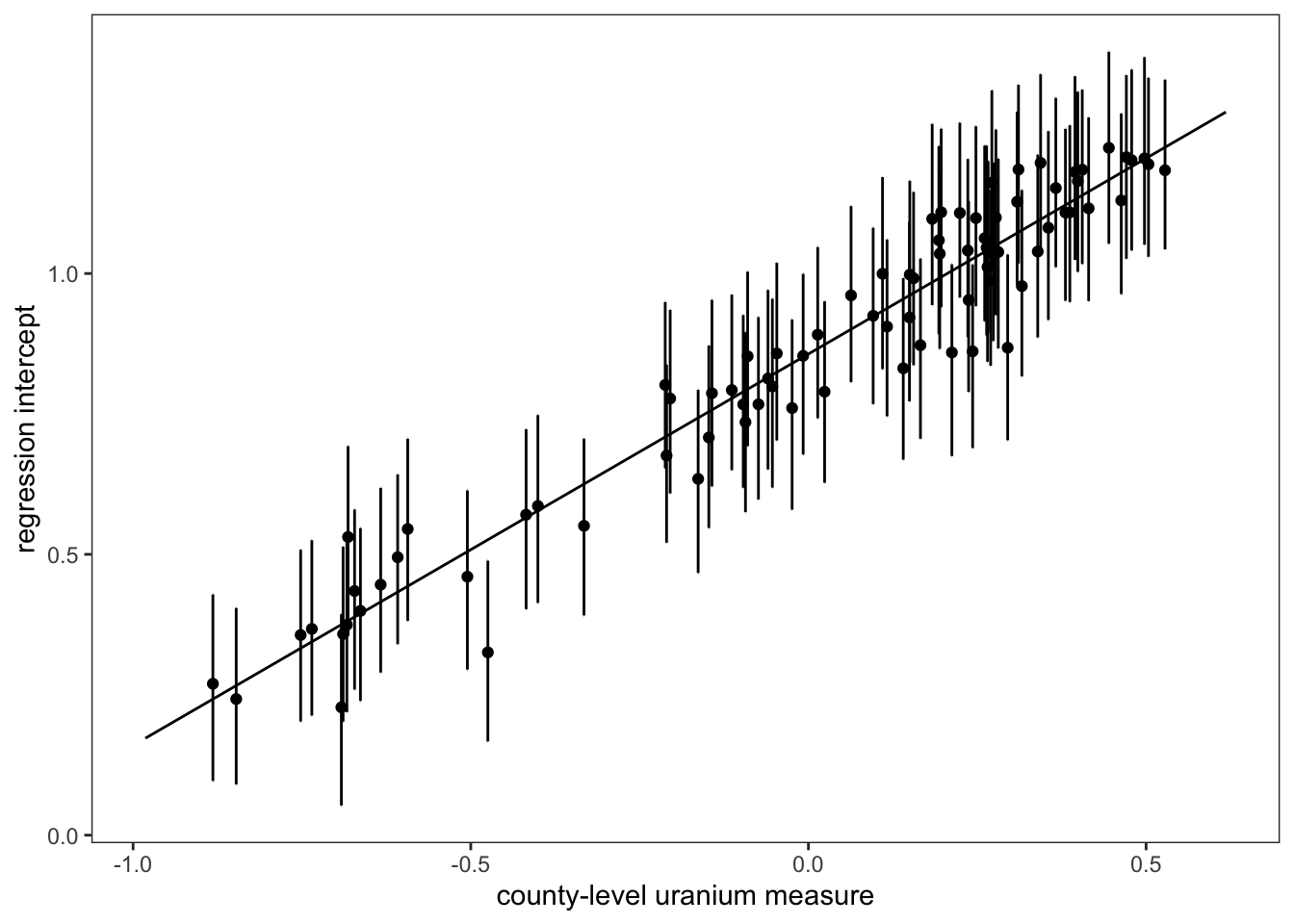
References
Gelman, Andrew. 2006. “Multilevel (Hierarchical) Modeling: What It Can and Cannot Do.” Technometrics 48 (3): 432–35. https://doi.org/10.1198/004017005000000661.
Price, P. N., A. V. Nero, and A. Gelman. 1996. “Bayesian Prediction of Mean Indoor Radon Concentrations for Minnesota Counties.” Health Physics 71 (6): 922–36. https://doi.org/10.1097/00004032-199612000-00009.
Citation
BibTeX citation:
@online{zelner2023,
author = {Zelner, Jon},
title = {Re-Creating the `Radon` Teaching Example with Rstanarm and
Tidybayes},
date = {2023-02-15},
url = {https://zelnotes.io/posts/radon},
langid = {en}
}
For attribution, please cite this work as:
Zelner, Jon. 2023. “Re-Creating the `Radon` Teaching Example with
Rstanarm and Tidybayes.” February 15, 2023. https://zelnotes.io/posts/radon.