Measuring spatial and contextual variation
EPID 594
Spatial Epidemiology
University of Michigan School of Public Health
Jon Zelner
[email protected]
epibayes.io
![]()
Today’s Theme
Making the most of multi-level data using hierarchical models
NO!

Complete pooling ignores potential sources of observed and unobserved unit-level confounding.
Your residuals should look like this
Residuals for a model with un-clustered errors
Your residuals should look like this
Residuals for a model with un-clustered errors
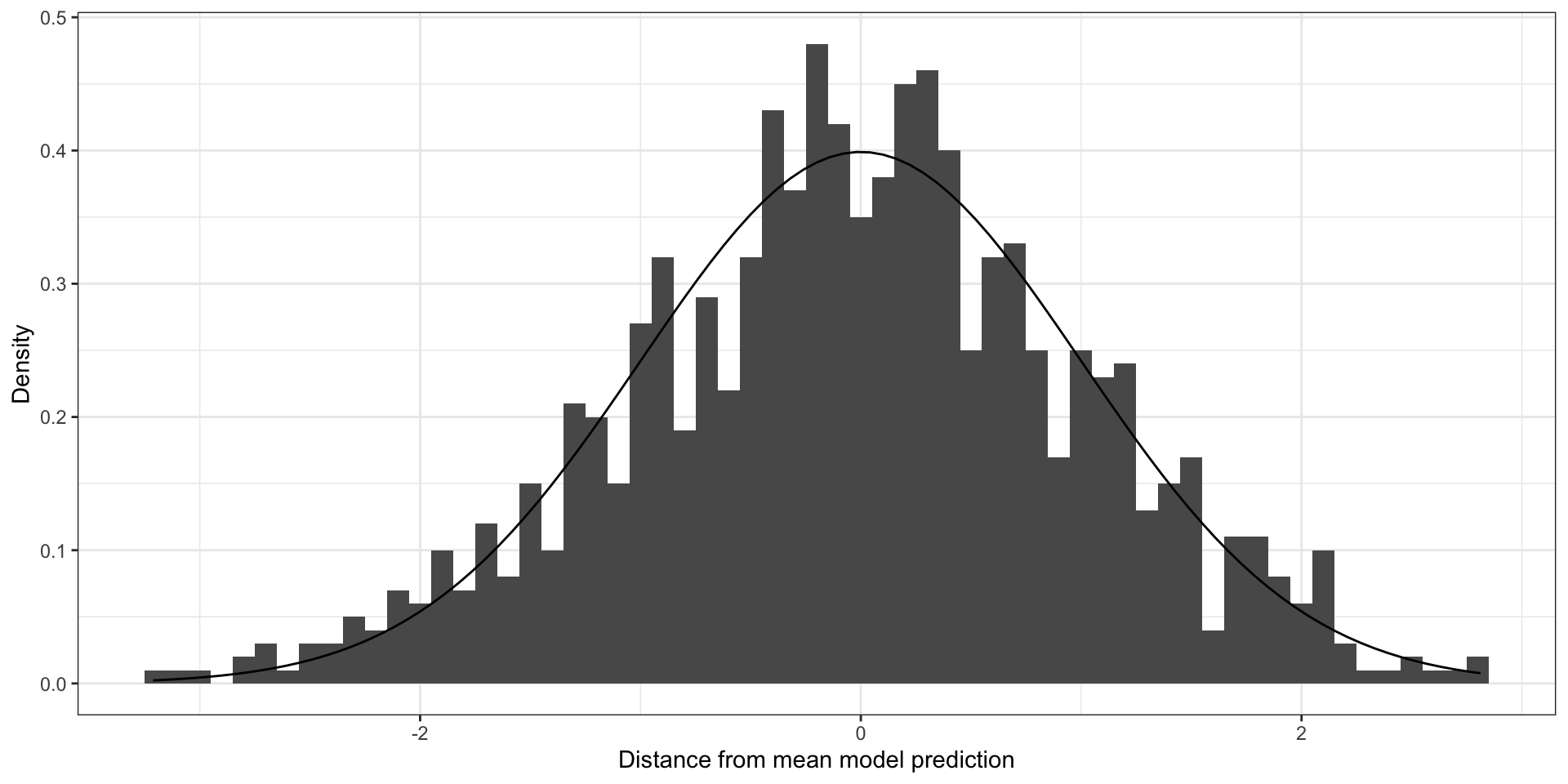
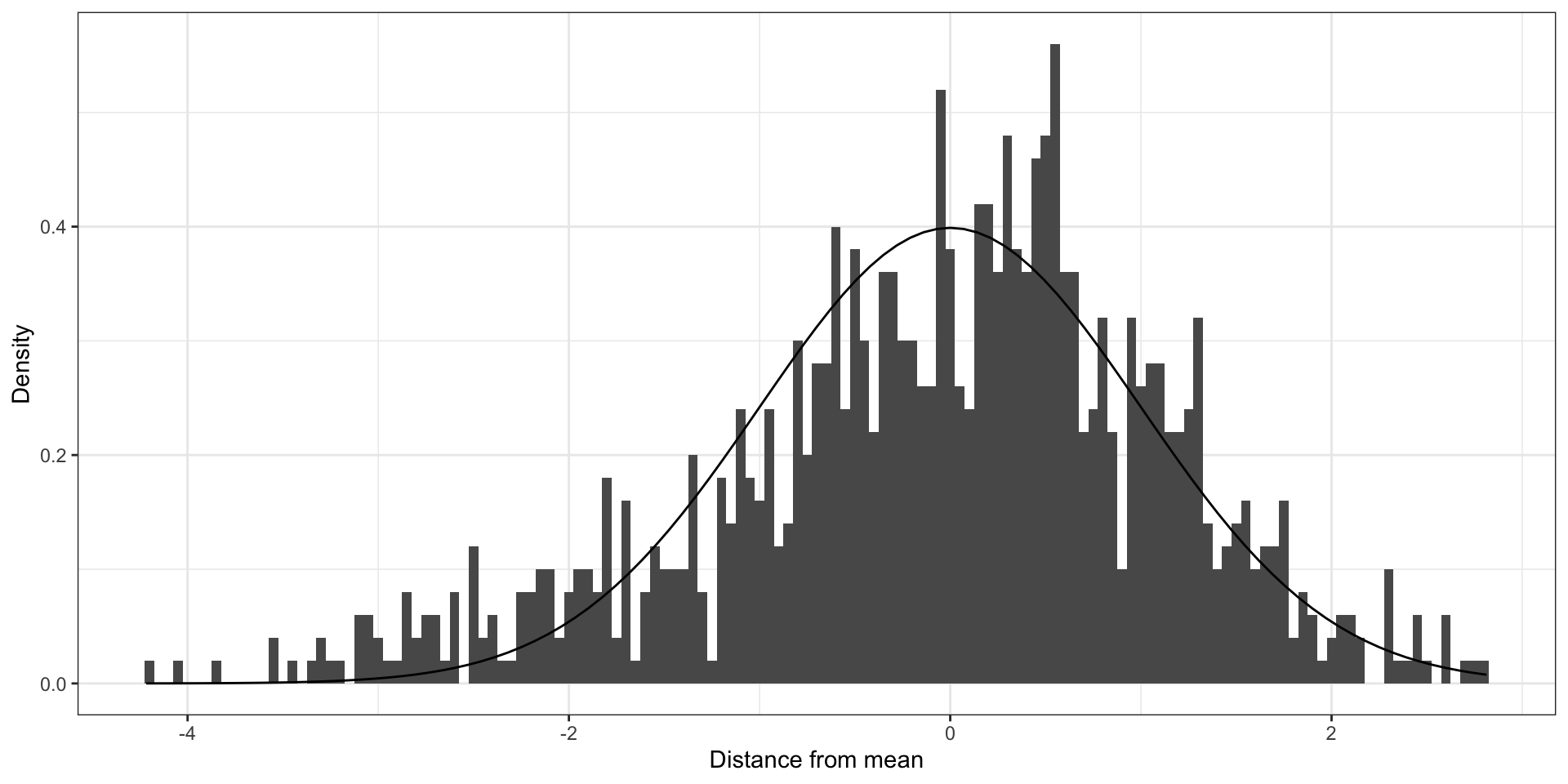
If you ignore strong 💪 clustering (ICC = 0.9)
Code
require(ggplot2)
icc <- 0.9
total_var <- 1
cluster_sigma <- sqrt(icc * total_var)
ind_sigma <- sqrt((1 - icc) * total_var)
ind_cluster <- 100
ncluster <- 10
cluster_ids <- sort(rep(1:ncluster, ind_cluster))
cluster_means <- rnorm(ncluster, sd = cluster_sigma)
ind_vals <- rnorm(n = length(cluster_ids), mean = cluster_means[cluster_ids], sd = ind_sigma)
df <- data.frame(x = ind_vals, cluster = cluster_ids)
g <- ggplot(df, aes(x = x, cluster = cluster_ids)) +
geom_histogram(binwidth = 0.05, aes(y=..density..)) +
xlab("Distance from mean") +
ylab("Density") +
stat_function(fun = dnorm, args = list(mean = 0, sd = sqrt(total_var))) +
theme_bw()
plot(g)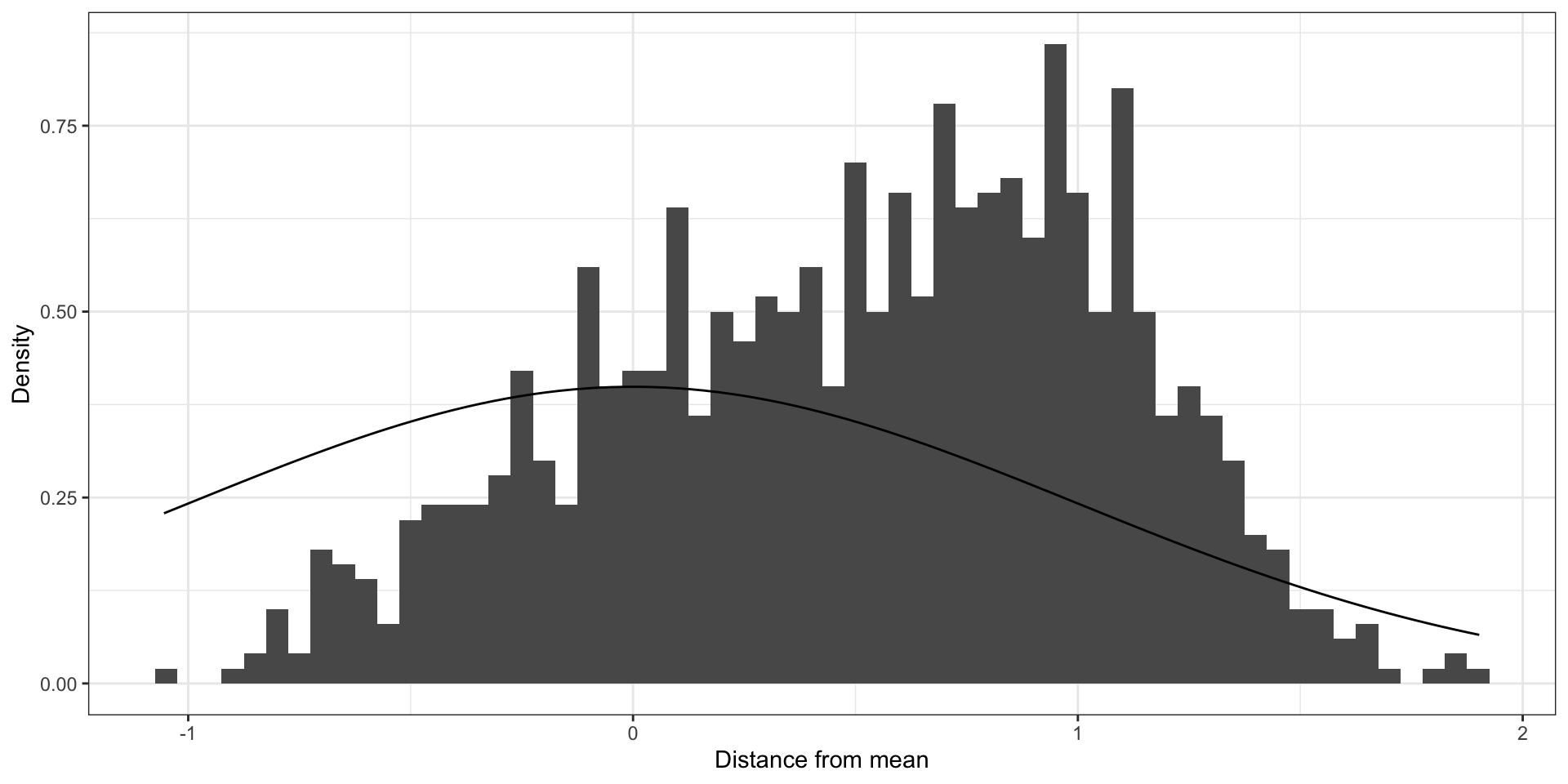
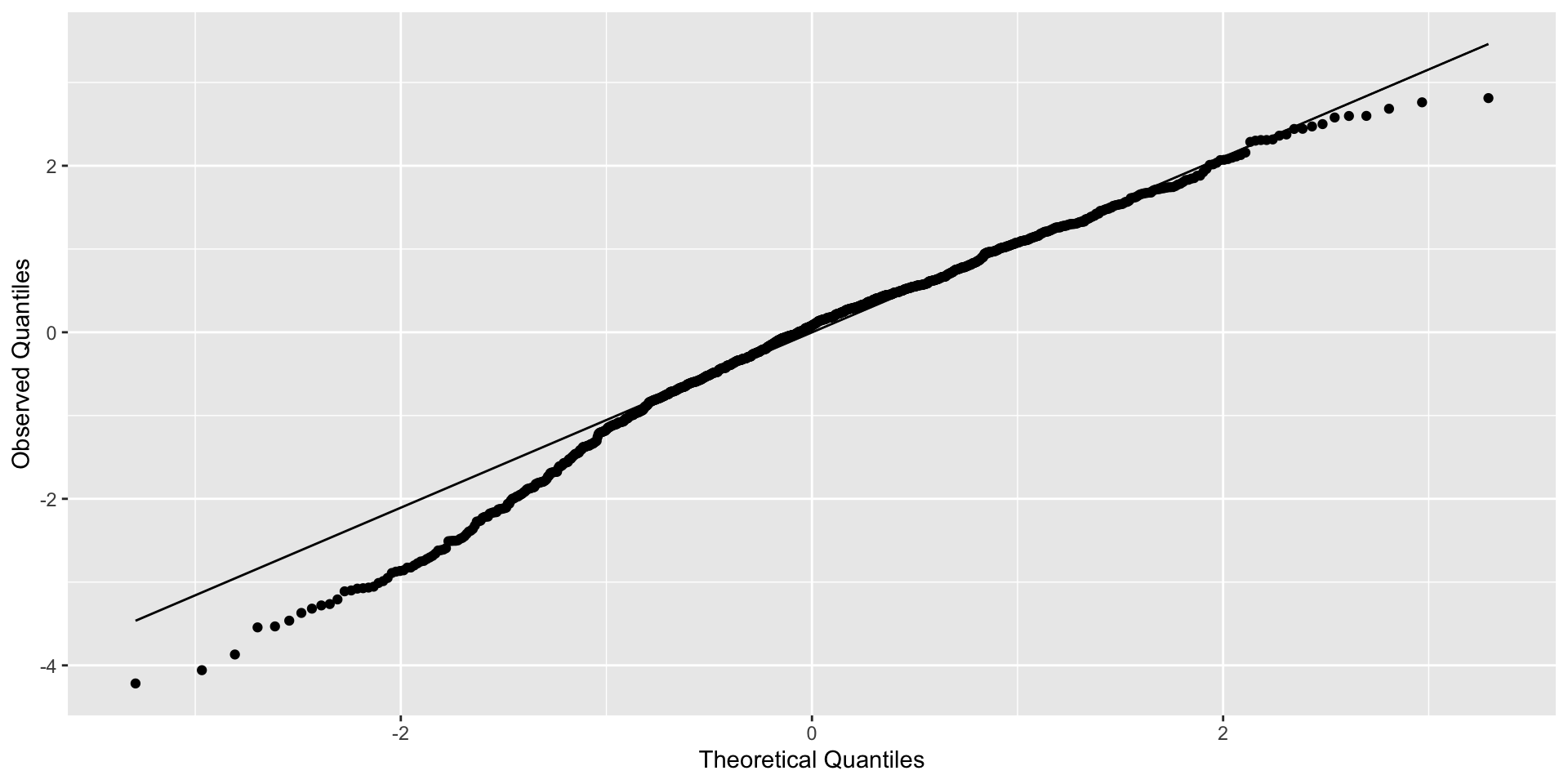
Clustered errors that are far from being normal
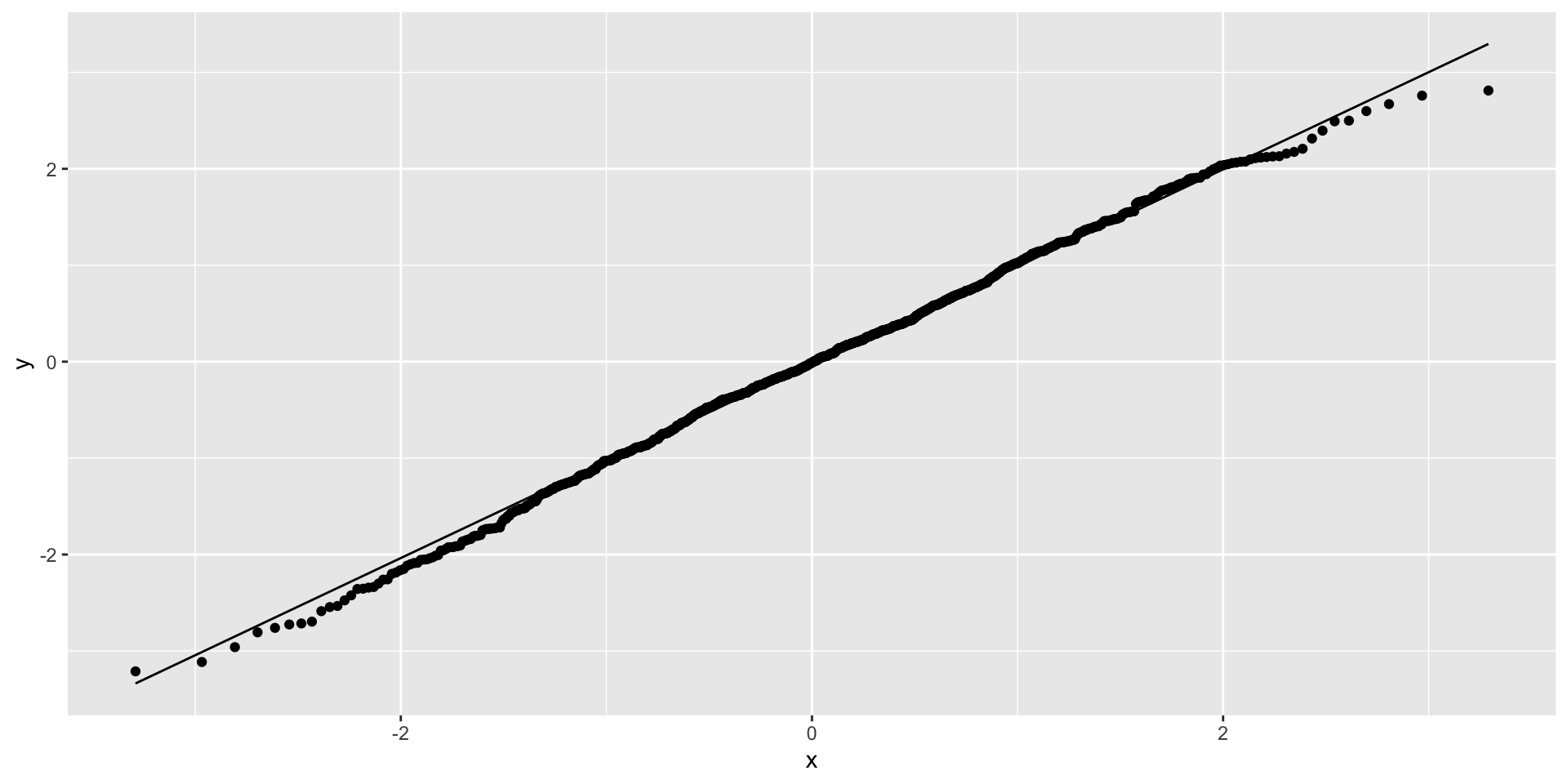
If you ignore strong 💪 clustering (ICC = 0.9)
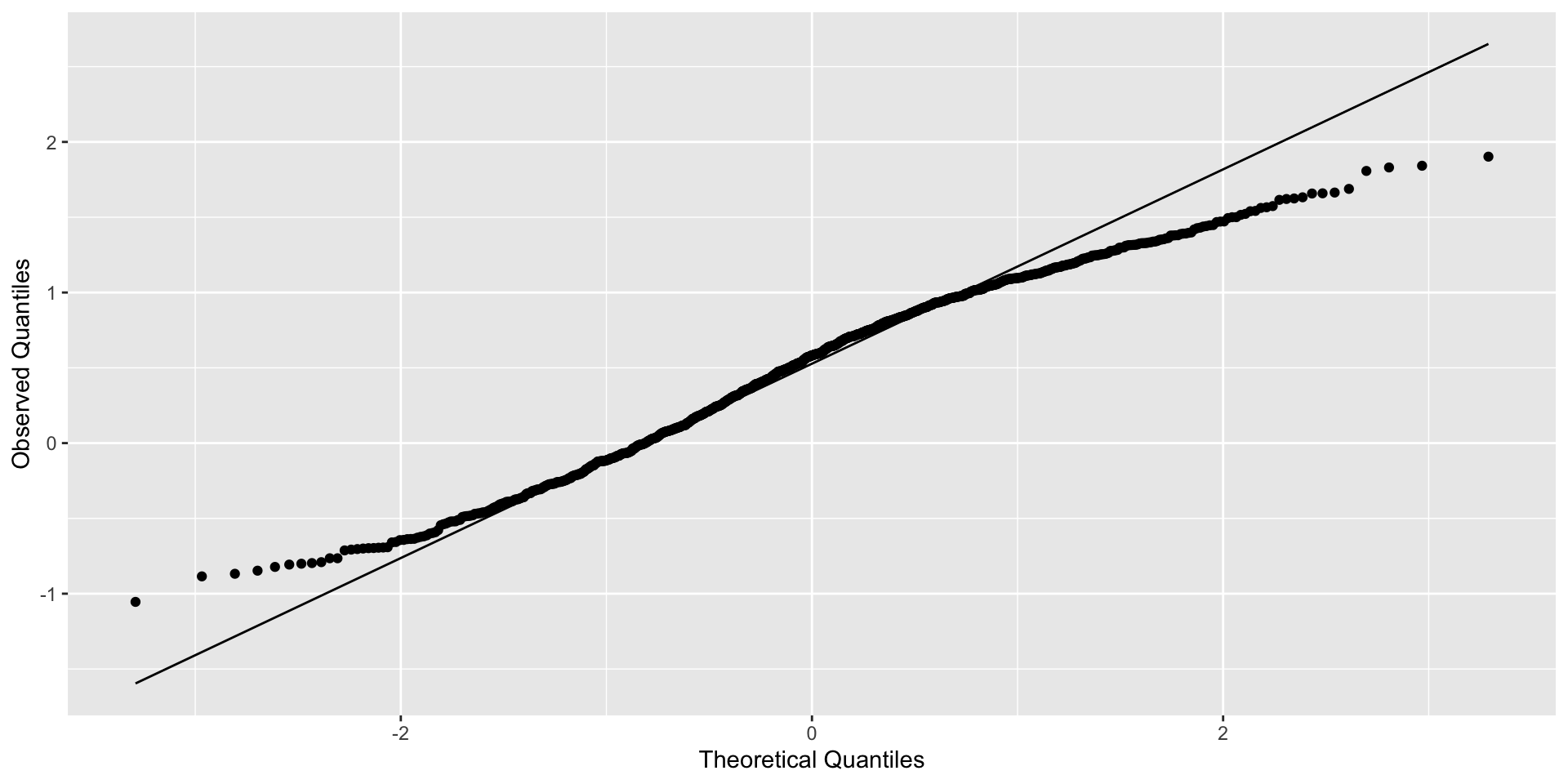
Qqplot of residuals
If you ignore moderate clustering (ICC = 0.5)
Moderately clustered errors
If you ignore moderate clustering (ICC = 0.5)
Example of residuals for model with clustered errors
If you ignore weaker clustering (ICC = 0.25)
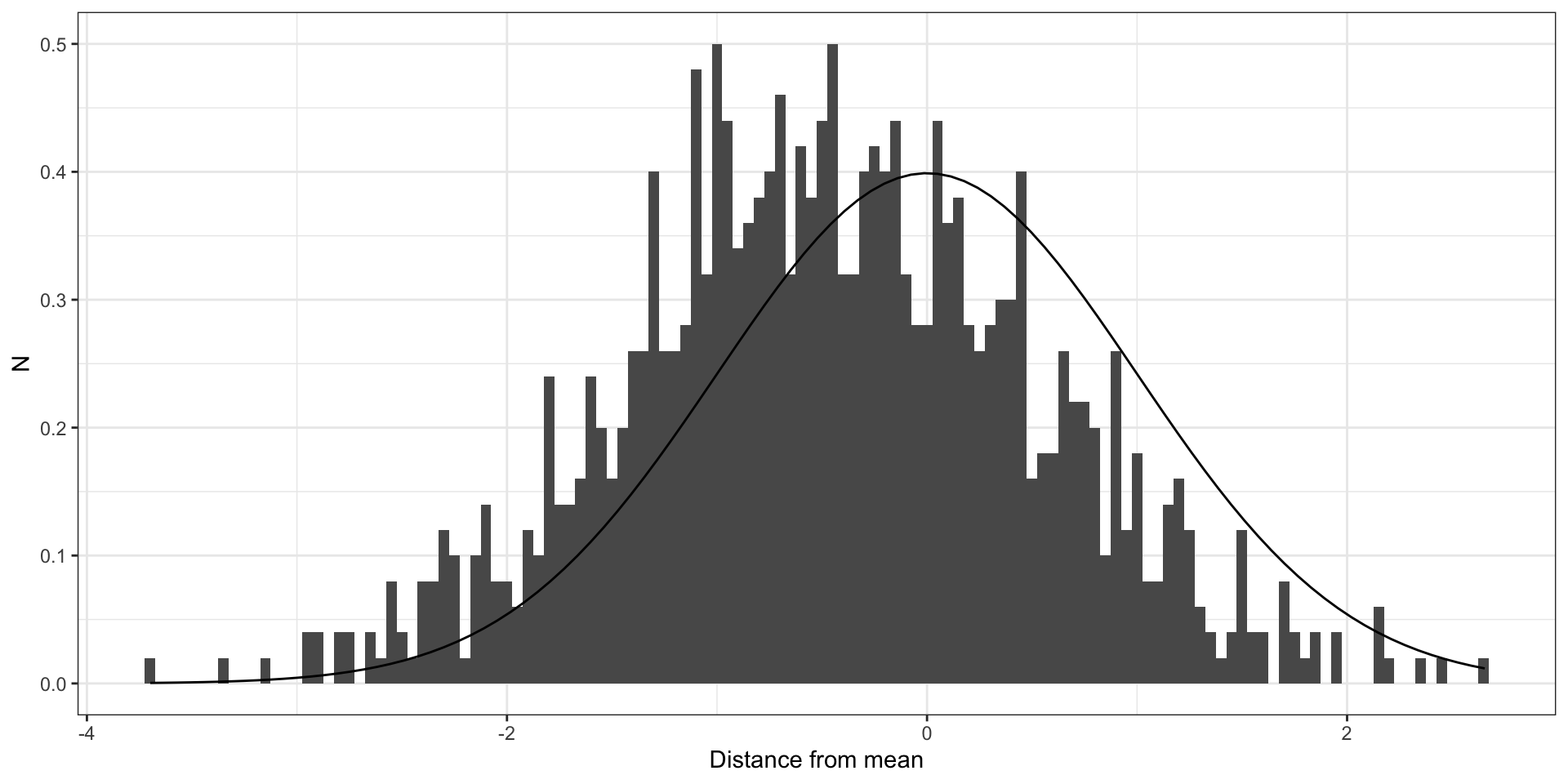
Clustered errors
If you ignore weaker clustering (ICC = 0.25)
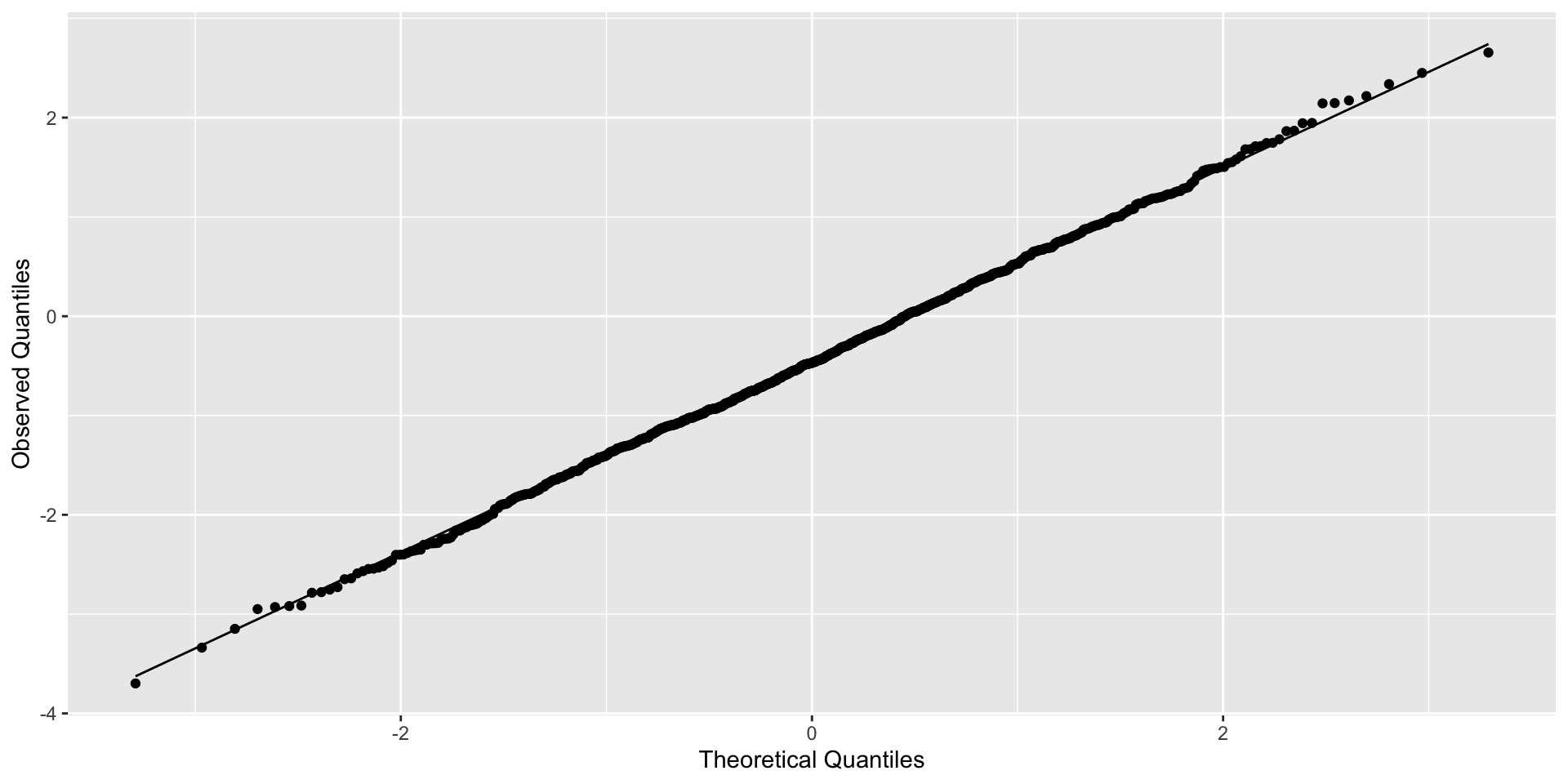
Example of residuals for model with clustered errors
More danger!

Totally unpooled models run the risk of overfitting the data, particularly in small samples.
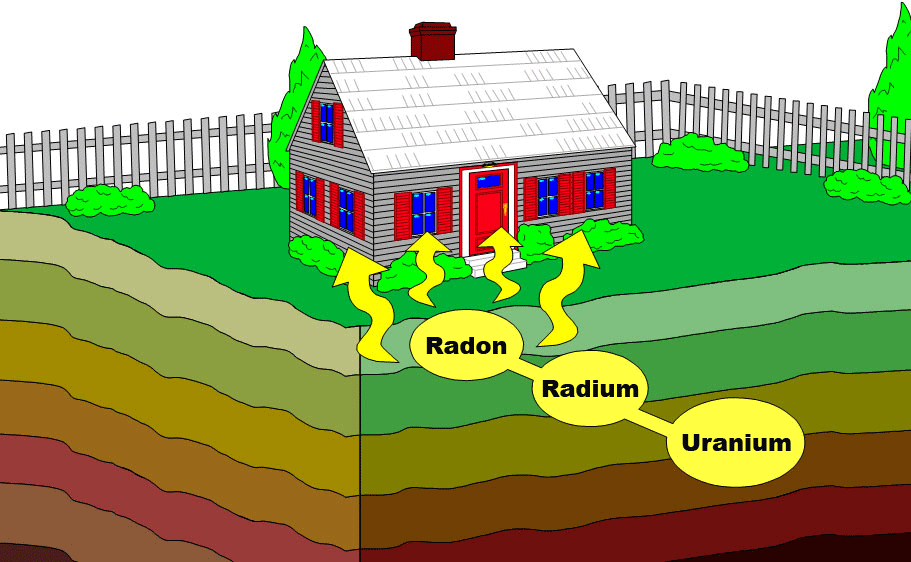
Imagine you’re in the radon system business

My very own radon mitigation system!
As the soil uranium ☢️ increases, so does baseline county-level radon
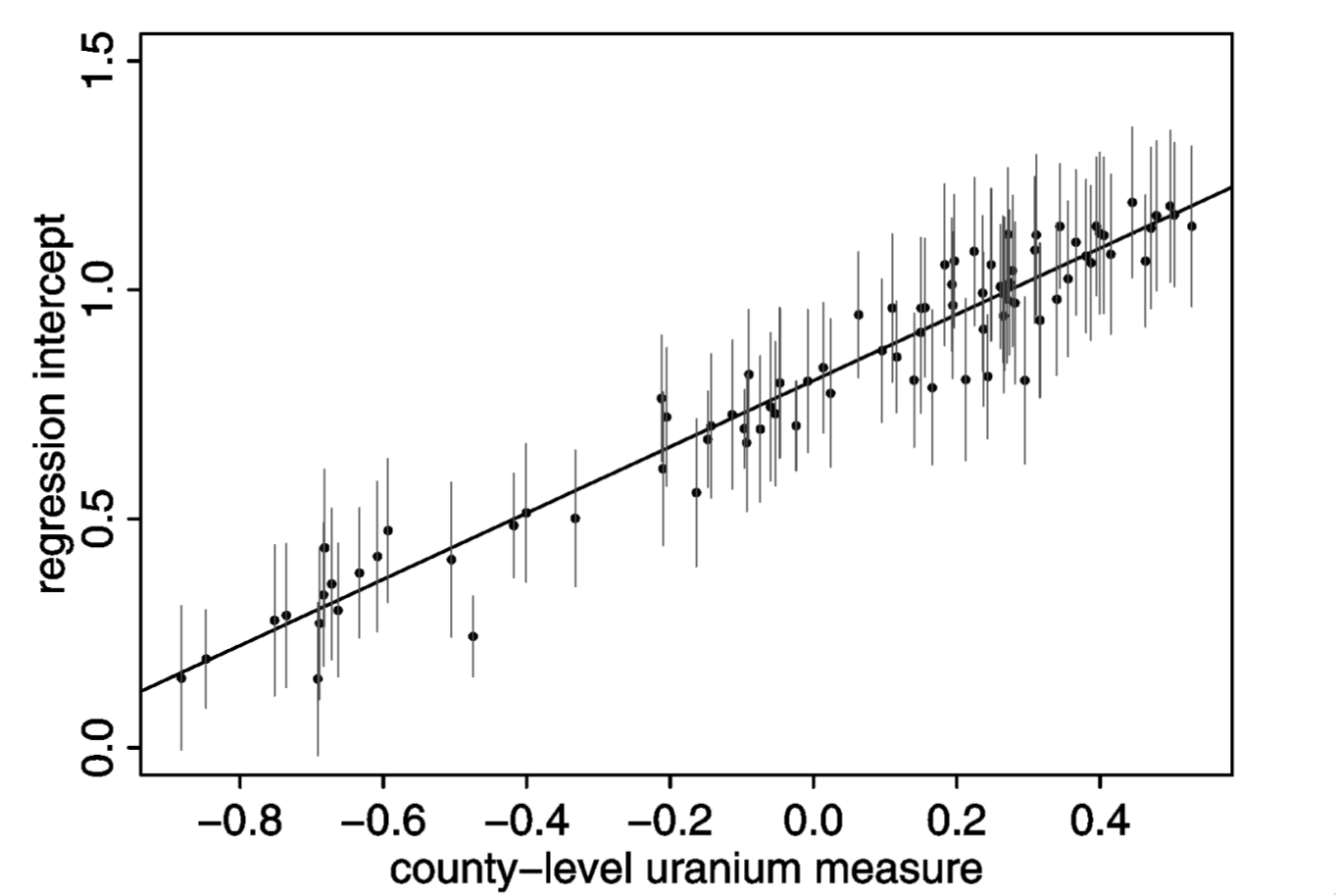
Counties with lots of soil uranium seem like a good bet for business
Partial pooling most benefits predictions for places with less data
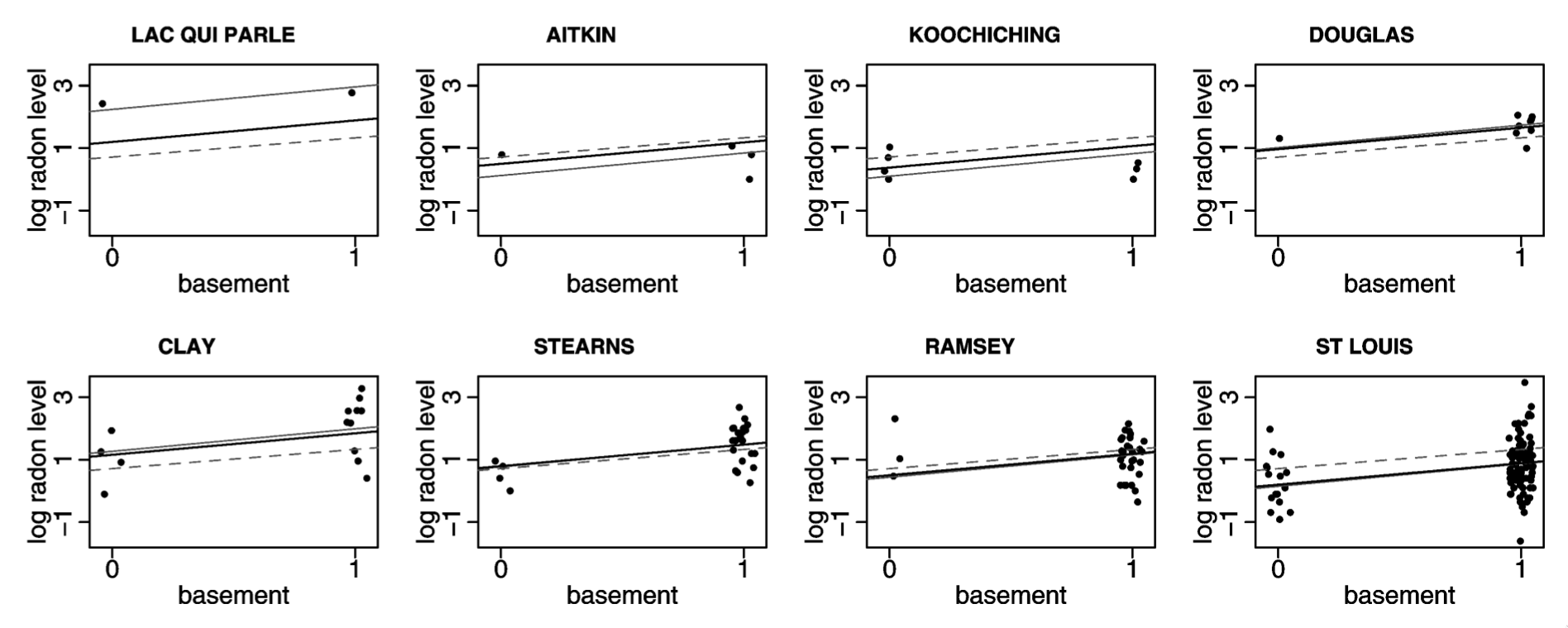
Light dotted line = full pooling; Light solid line = no pooling; Dark line = partial pooling
Time for a test-drive! 🏎️